How should one make graphics that appropriately compare models and observations? There are basically two key points (explored in more depth here) – comparisons should be ‘like with like’, and different sources of uncertainty should be clear, whether uncertainties are related to ‘weather’ and/or structural uncertainty in either the observations or the models. There are unfortunately many graphics going around that fail to do this properly, and some prominent ones are associated with satellite temperatures made by John Christy. This post explains exactly why these graphs are misleading and how more honest presentations of the comparison allow for more informed discussions of why and how these records are changing and differ from models.
The dominant contrarian talking point of the last few years has concerned the ‘satellite’ temperatures. The almost exclusive use of this topic, for instance, in recent congressional hearings, coincides (by total coincidence I’m sure) with the stubborn insistence of the surface temperature data sets, ocean heat content, sea ice trends, sea levels, etc. to show continued effects of warming and break historical records. To hear some tell it, one might get the impression that there are no other relevant data sets, and that the satellites are a uniquely perfect measure of the earth’s climate state. Neither of these things are, however, true.
The satellites in question are a series of polar-orbiting NOAA and NASA satellites with Microwave Sounding Unit (MSU) instruments (more recent versions are called the Advanced MSU or AMSU for short). Despite Will Happer’s recent insistence, these instruments do not register temperatures “just like an infra-red thermometer at the doctor’s”, but rather detect specific emission lines from O2 in the microwave band. These depend on the temperature of the O2 molecules, and by picking different bands and different angles through the atmosphere, different weighted averages of the bulk temperature of the atmosphere can theoretically be retrieved. In practice, the work to build climate records from these raw data is substantial, involving inter-satellite calibrations, systematic biases, non-climatic drifts over time, and perhaps inevitably, coding errors in the processing programs (no shame there – all code I’ve ever written or been involved with has bugs).
Let’s take Christy’s Feb 16, 2016 testimony. In it there are four figures comparing the MSU data products and model simulations. The specific metric being plotted is denoted the Temperature of the “Mid-Troposphere” (TMT). This corresponds to the MSU Channel 2, and the new AMSU Channel 5 (more or less) and integrates up from the surface through to the lower stratosphere. Because the stratosphere is cooling over time and responds uniquely to volcanoes, ozone depletion and solar forcing, TMT is warming differently than the troposphere as a whole or the surface. It thus must be compared to similarly weighted integrations in the models for the comparisons to make any sense.
The four figures are the following:
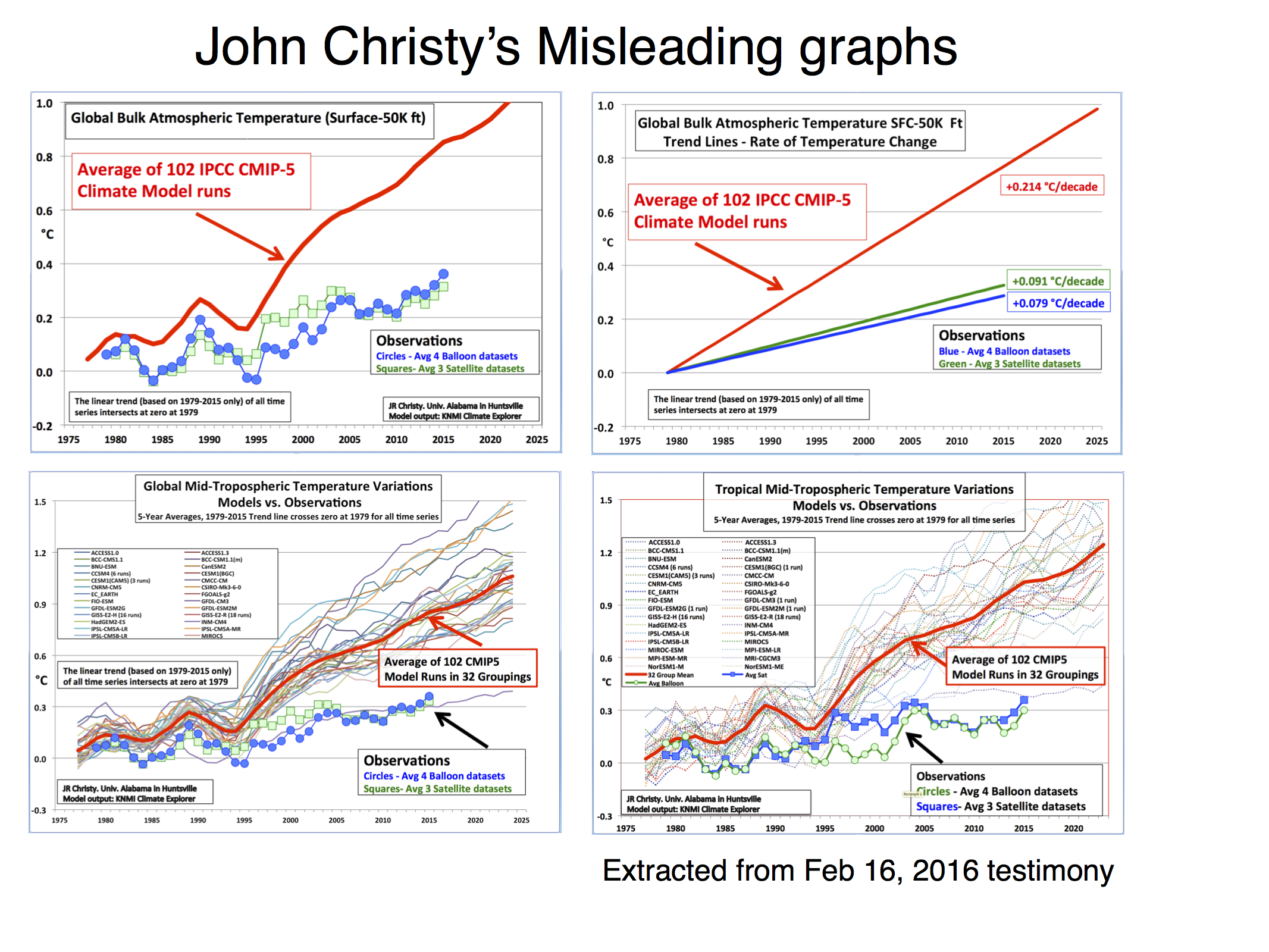
There are four decisions made in plotting these graphs that are problematic:
- Choice of baseline,
- Inconsistent smoothing,
- Incomplete representation of the initial condition and structural uncertainty in the models,
- No depiction of the structural uncertainty in the satellite observations.
Each of these four choices separately (and even more so together) has the effect of making the visual discrepancy between the models and observational products larger, misleading the reader as to the magnitude of the discrepancy and, therefore, it’s potential cause(s).
To avoid discussions of the details involved in the vertical weighting for TMT for the CMIP5 models, in the following, I will just use the collation of this metric directly from John Christy (by way of Chip Knappenburger). This is derived from public domain data (historical experiments to 2005 and RCP45 thereafter) and anyone interested can download it here. Comparisons of specific simulations for other estimates of these anomalies show no substantive differences and so I’m happy to accept Christy’s calculations on this. Secondly, I am not going to bother with the balloon data to save clutter and effort; None of the points I want to make depend on this.
In all that follows, I am discussing the TMT product, and as a shorthand, when I say observations, I mean the observationally-derived TMT product. For each of the items, I’ll use the model ensemble to demonstrate the difference the choices make (except for the last one), and only combine things below.
1. Baselines
Worrying about baseline used for the anomalies can seem silly, since trends are insensitive to the baseline. However there are visual consequences to this choice. Given the internal variability of the system, baselines to short periods (a year or two or three) cause larger spreads away from the calibration period. Picking a period that was anomalously warm in the observations pushes those lines down relative to the models exaggerating the difference later in time. Longer periods (i.e. decadal or longer) have a more even magnitude of internal variability over time and so are preferred for enhancing the impact of forced (or external) trends. For surface temperatures, baselines of 20 or 30 years are commonplace, but for the relatively short satellite period (37 years so far) that long a baseline would excessively obscure differences in trends, so I use a ten year period below. Historically, Christy and Spencer have use single years (1979) or short periods (1979-1983), however, in the above graphs, the baseline is not that simple. Instead the linear trend through the smoothed record is calculated and the baseline of the lines is set so the trend lines all go through zero in 1979. To my knowledge this is a unique technique and I’m not even clear on how one should label the y-axis.
To illustrate what impact these choices have, I’ll use the models in graphics that use for 4 different choices. I’m using the annual data to avoid issues with Christy’s smoothing (see below) and I’m plotting the 95% envelope of the ensemble (so 5% of simulations would be expected to be outside these envelopes at any time if the spread was Gaussian).

Using the case with the decade-long baseline (1979-1988) as a reference, the spread in 2015 with the 1979 baseline is 22% wider, with 1979-1983, it’s 7% wider, and the case with the fixed 1979-2015 trendline, 10% wider. The last case is also 0.14ºC higher on average. For reference, the spread with a 20 and 30 year baseline would be 7 and 14% narrower than the 1979-1988 baseline case.
2. Inconsistent smoothing
Christy purports to be using 5-yr running mean smoothing, and mostly he does. However at the ends of the observational data sets, he is using a 4 and then 3-yr smoothing for the two end points. This is equivalent to assuming that the subsequent 2 years will be equal to the mean of the previous 3 and in a situation where there is strong trend, that is unlikely to be true. In the models, Christy correctly calculates the 5-year means, therefore increasing their trend (slightly) relative to the observations. This is not a big issue, but the effect of the choice also widens the discrepancy a little. It also affects the baselining issue discussed above because the trends are not strictly commensurate between the models and the observations, and the trend is used in the baseline. Note that Christy gives the trends from his smoothed data, not the annual mean data, implying that he is using a longer period in the models.

This can be quantified, for instance, the trend in the 5yr-smoothed ensemble mean is 0.214ºC/dec, compared to 0.210ºC/dec on the annual data (1979-2015). For the RSS v4 and UAH v6 data the trends on the 5yr-smooth w/padding are 0.127ºC/dec and 0.070ºC/dec respectively, compared to the trends on the annual means of 0.129ºC/dec and 0.072ºC/dec. These are small differences, but IMO a totally unnecessary complication.
3. Model spread
The CMIP5 ensemble is what is known as an ‘ensemble of opportunity’, it contains many independent (and not so independent) models, with varying numbers of ensemble members, haphazardly put together by the world’s climate modeling groups. It should not be seen as a probability density function for ‘all plausible model results’, nonetheless, it is often used as such implicitly. There are three sources of variation across this ensemble. The easiest to deal with and the largest term for short time periods is initial condition uncertainty (the ‘weather’); if you take the same model, with the same forcings and perturb the initial conditions slightly, the ‘weather’ will be different in each run (El Niño’s will be in different years etc.). Second, is the variation in model response to changing forcings – a more sensitive model will have a larger response than a less sensitive model. Thirdly, there is variation in the forcings themselves, both across models and with respect to the real world. There should be no expectation that the CMIP5 ensemble samples the true uncertainties in these last two variations.
Plotting all the runs individually (102 in this case) generally makes a mess since no-one can distinguish individual simulations. Grouping them in classes as a function of model origin or number of ensemble members reduces the variance for no good reason. Thus, I mostly plot the 95% envelope of the runs – this is stable to additional model runs from the same underlying distribution and does not add to excessive chart junk. You can see the relationship between the individual models and the envelope here:

4. Structural uncertainty in the observations
This is the big one. In none of the Christy graphs is there any indication of what the variation of the trend or the annual values are as a function of the different variations in how the observational MSU TMT anomalies are calculated. The real structural uncertainty is hard to know for certain, but we can get an idea by using the satellite products derived either by different methods by the same group, or by different groups. There are two recent versions of both RSS and UAH, and independent versions developed by NOAA STAR, and for the tropics only, a group at UW. However this is estimated, it will cause a spread in the observational lines. And this is where the baseline and smoothing issues become more important (because a short baseline increases the later spread) not showing the observational spread effectively makes the gap between models and observations seem larger.

Summary
Let’s summarise the issues with Christy’s graphs each in turn:
- No model spread, inconsistent smoothing, no structural uncertainty in the satellite observations, weird baseline.
- No model spread, inconsistent trend calculation (though that is a small effect), no structural uncertainty in the satellite observations. Additionally, this is a lot of graph to show only 3 numbers.
- Incomplete model spread, inconsistent smoothing, no structural uncertainty in the satellite observations, weird baseline.
- Same as the previous graph but for the tropics-only data.
What then would be alternatives to these graphs that followed more reasonable conventions? As I stated above, I find that model spread is usefully shown using a mean and 95% envelope, smoothing should be consistent (though my preference is not to smooth the data beyond the annual mean so that padding issues don’t arise), the structural uncertainty in the observational datasets should be explicit and baselines should not be weird or distorting. If you only want to show trends, then a histogram is a better kind of figure. Given that, the set of four figures would be best condensed to two for each metric (global and tropical means):




The trend histograms show far more information than Christy’s graphs, including the distribution across the ensemble and the standard OLS uncertainties on the linear trends in the observations. The difference between the global and tropical values are interesting too – there is a small shift to higher trends in the tropical values, but the uncertainty too is wider because of the greater relative importance of ENSO compared to the trend.
If the 5-year (padded) smoothing is really wanted, the first graphs would change as follows (note the trend plots don’t change):


but the last two years will change as new data comes in.
So what?
Let’s remember the point here. We compare models and observations to learn something about the real world, not just to score points in some esoteric debate. So how does a better representation of the results help? Firstly, while the apparent differences are reduced in the updated presentation, they have not disappeared. But understanding how large the real differences actually are puts us in a better position to look for plausible reasons for them. Christy’s graphs are designed to lead you to a single conclusion (that the models are too sensitive to forcings), by eliminating consideration of the internal variability and structural uncertainty in the observations.
But Christy also ignores the importance of what forcings were used in the CMIP5 simulations. In work we did on the surface temperatures in CMIP5 and the real world, it became apparent that the forcings used in the models, particularly the solar and volcanic trends after 2000, imparted a warm bias in the models (up to 0.1ºC or so in the ensemble by 2012), which combined with the specific sequence of ENSO variability, explained most of the model-obs discrepancy in GMST. This result is not simply transferable to the TMT record (since the forcings and ENSO have different fingerprints in TMT than at the surface), but similar results will qualitatively hold. Alternative explanations – such as further structural uncertainty in the satellites, perhaps associated with the AMSU sensors after 2000, or some small overestimate of climate sensitivity in the model ensemble are plausible, but as yet there is no reason to support these ideas over the (known) issues with the forcings and ENSO. Some more work is needed here to calculate the TMT trends with updated forcings (soon!), and that will help further clarify things. With 2016 very likely to be the warmest year on record in the satellite observations the differences in trend will also diminish.
The bottom line is clear though – if you are interested in furthering understanding about what is happening in the climate system, you have to compare models and observations appropriately. However, if you are only interested in scoring points or political grandstanding then, of course, you can do what you like.
PS: I started drafting this post in December, but for multiple reasons didn’t finish it until now, updating it for 2015 data and referencing Christy’s Feb 16 testimony. I made some of these points on twitter, but some people seem to think that is equivalent to “mugging” someone. Might as well be hung for a blog post than a tweet though…
How much did you want to bet?
I doubt anyone here will argue with the proposition that the models are wrong.
That’s well understood.
Ways of making them more useful should attract attention. I see your papers cited quite a few places, e.g. http://www.sciencedirect.com/science/article/pii/S0074614200800650
Was your 1989 paper useful to improve the weather and climate models available at the time?
Have the faster computers available now made this sort of change more, or less, needed?
P.S., Dr. Browning, since your retirement, you have had some acerbic exchanges here and elsewhere quoted on your web page — page down here: http://www.zoominfo.com/p/Gerald-Browning/1419843363
I’m just a reader on the topic, not a climate scientist, and can’t weigh the arguments being made. But I have an old friend who was being competed for not long ago by both NCAR and Microsoft (he turned them both down and went and started a company, sold it, started another one, the serial entrepreneur at work). And his stories about the, um, sharp-edged arguments among numeric modelers made them sound especially fractious.
It must be hard to get good work to appear out of the smoke and lightning bolts that get thrown about so freely.
P.S., op. cit.:
https://www.realclimate.org/index.php/archives/2008/05/what-the-ipcc-models-really-say/comment-page-4/
Gerald, your comment will surely disappear from my memory, because I didn’t follow the link, which is guaranteed useless, to far more than 5 nines.
Well maybe they forgot?
…. https://www.realclimate.org/index.php/archives/2008/05/what-the-ipcc-models-really-say/comment-page-8/#comment-88054
Exactly the quality of scientific arguments that I would expect from this fine site. Not one capable of applying any theory to refute the facts. So then start trying to
denigrate the person. My credentials speak for themselves. I challenge any of you to
refute the presentation on the link at climate audit where name calling is not permitted. I await your responses there. And BTW I am fully aware what junk is in the climate models.
Jerry
Hank,
It is very clear that you did not read our 2002 manuscript. It is not more computing power that is needed but better theory.
Can you state the Lax equivalence theorem, or is he also not recognized by this site?
Jerry
97, Kevin McKinney: If the ‘pause’ was due largely to natural variability, then we may very well see a period of ‘accelerated’ warming once again, as for instance in the ‘post-Pinatubo’ period leading up to 1998.
Yes we may.
GB 106, I note your paper is not in a peer-reviewed journal, but merely put up on a web site. Why is that? Just wondering.
Matthew Marler, 96: On what “the GCMs are useful now” means, the current lead post, on the AMOC, is a good place to start.
“Exactly the quality of scientific arguments that I would expect from this fine site.”
So why post here, then? This site is intended to communicate climate science to a non-specialist audience, not refashion climate models–there are, you know, actual journals for that.
On a purely human level, I feel obliged to point out that you came in the door with a huge chip on your shoulder.
Lax-Richtmyer? No, I can’t state that. Not a mathematician.
You probably aren’t reaching the people you’re trying to have a conversation with, if that’s a threshold requirement.
I see why you were banned from the site years ago. Hope things have gotten better for you since retirement.
The folks at ClimateAudit are very friendly and will take you in wholeheartedly.
Trust but verify, though.
Gerald Browning:
Considering the list of principal contributors to this site, it’s not a place to brag about one’s credentials. OTOH, like Hank Roberts, many of the regular commenters here aren’t working climate scientists but merely interested laypersons. Why would we attempt to “refute” a presentation on a blog devoted to AGW-denial?
You have a substantial publication record, so you should know that meaningful scientific debate takes place in appropriate venues, under well-established rules. If you want your claim to be taken seriously on RC, present it at, say, the annual AGU Fall Meeting. Or submit your manuscript for publication in one of the established refereed journals you’ve published in previously. FWIW, I for one would be more inclined to read it then.
Mal,
I presented this poster at the EGU Conference in Vienna last month.
http://meetingorganizer.copernicus.org/EGU2016/EGU2016-18088.pdf
http://presentations.copernicus.org/EGU2016-18088_presentation.pdf
It explains why the models and radiosondes do not agree. In effect, CO2 only warms the Earth surface and the resulting change in snowline drives the global temperature as a result of albedo change.
Jeez, you’re telling me this Gerald Browning is a known and published scientist? The conspiracy ideation and bratty self-pity are right down there with your average basement-dwelling internet crackpot. Sad.
If he deigns to take notice of my comment, I’m sure he’ll whine about my nasty tone. Being, of course, a model of polite decorum in his own comments.
but, but, Alastair, mean free path: http://rabett.blogspot.com/2013/04/this-is-where-eli-came-in.html
Back to the basics.
There is an unambiguous and clear target, widely published: The climate should not warm by more than 2 degC, preferably much less.
Is there a corresponding, unambiguous, clear and widely published metric stating where we stand now? No there is not. Any day,from the various publications you can choose whichever number you wish. Some say 0,1 degC, some 0,4 degC, some 1,5 degC, all from respectable scientists and major agencies. Try reading the NOAA and WMO messages, for instance.
Yes, I know why. I also know that every scientist likes to have his/her very own, best method of communicating his/her research results, with all the relevant caveats. It is the reader’s responsibility to understand what is said and he/she is expected to make the needed effort to do so. However, the average voter does not have the time or inclination or skills. People vote on the climate issues in every election, based on the number uppermost in their minds.
Maybe something could be done to improve this.
Gerald Browning,
I’m sure you’ve flitted away to brag about how witty and bold you commentary was, but a question: If you’ve indeed found a shortcoming in the models, then why have you not build your own climate model with the correct dynamics? It should be well within your capabilities, and after all, that is what a real scientist would do.
110, Patrick: Matthew Marler, 96: On what “the GCMs are useful now” means, the current lead post, on the AMOC, is a good place to start.
Good read. Thank you.
good article at Tamino on models:
https://tamino.wordpress.com/2016/05/17/models/#more-8548
and interesting discussion in comments as well including this in a response
“What worries me is unforseen feedbacks in the carbon cycle. I don’t worry much about the “methane bomb,” but the melting of permafrost and its consequent release of CO2 concerns me greatly. It could bring about a situation in which, even if we totally halt CO2 emissions, atmospheric concentration continues to rise dramatically.”
Mike says: if we get through the current el nino without triggering feedback loops that will continue record heat in the balance of 2016 and 2017, I think we emerge from this kinda scary el nino event with CO2 levels in excess of the 405 ppm that Michael Mann said we should avoid. I am watching the record jumps in CO2 ppm (4 ppm for March 2016 over March 2015) and hoping that we are not seeing the “unforseen” feedbacks in the carbon cycle.
One thing I don’t get is how anyone who has followed global warming closely can describe these feedbacks as unforseen. I think it has been clear that there are numerous feedback potentials and they almost all go the wrong direction in terms of ghg accumulation in the atmosphere. The triggering and impact of these feedbacks are difficult to predict and I understand that a knowledgeable person might discount these feedbacks, but I think the kind of feedbacks that tamino is thinking about in this comment have been foreseen and are in the realm of bad possibilities that should be at the forefront of the discussion about public policy responses to AGW.
Just sayin…
Warm regards
Mike
Re Gerald Browning — I think the issue is that no one can get the dynamics of ENSO close to the correct physics. But what Browning is concerned about is wayyy down in the weeds; akin to getting the turbulence modeling correct on the trailing edge of an airplane wing. That’s not important as long as you can get Bernoulli’s equation right and predict the lift — which is the equivalent of modeling CO2’s effect — what kind of lift we are getting from the forcing and the 1st-order response function. The consensus is that this 1st-order model is largely correct.
Yet there remains a knowledge gap regarding ENSO.
As far as I can tell, the big name in ENSO modeling is A.A. Tsonis, who has published a paper on the topic in the lauded Physical Review Letters. Tsonis is one of those that says ENSO is essentially chaotic and uses that to explain why it’s difficult to model. But now we find that Tsonis has this month joined the denier committee at the Global Warming Policy Foundation, alongside Richard Lindzen. Who is the authority on ENSO modeling? If it is indeed Tsonis, then :(
Hank,
you wrote “but, but, Alastair, mean free path: http://rabett.blogspot.com/2013/04/this-is-where-eli-came-in.html”
I am well aware of the part that the “mean free path” plays in absorption and emission by greenhouse gases. Fourier was not! He thought that the atmosphere, behaved like a sheet of glass in a Saussure hotbox (greenhouse), and his fans still believe that the radiation emitted from the surface of the Earth controls the balance of radiation at the top of the atmosphere.
The post that you linked goes wrong pretty quickly when it says: “Any collision can in principle change the amount of any of these forms of energy by any amount subject to conservation of energy and momentum.” It seems that Professor Rabett has not heard of quantum mechanics.
The rotational and vibrational forms of energy can only be changed by fixed amount of energy (quanta), and this means that emissions from vibrationally excited molecules are mostly “frozen out” at atmospheric temperature, because there are too few collisions with enough energy to excite the greenhouse gas molecules. Electronic emissions are totally frozen out.
This explains why greenhouse gases are net absorbers of radiation. They absorb all the radiation emitted by the surface but only emit based on the small number of molecules which are excited by collisions.
But you do not need to know all that to understand my poster. Have you read it?
Alastair, I recall asking years ago, probably at Stoat around 2005 — if CO2 were saturated near the ground, so every photon emitted from the ground would be intercepted, and the energy from those photons mixed into the atmosphere and spread around evenly — how do people take infrared photographs from above and see the ground in the infrared band? Wouldn’t the result be a bright fog, with no photons reaching the camera by line of sight?
#122, Mike–
Perhaps Tamino will clarify what he meant. But in the meantime, maybe he meant precisely what he said? That is, in addition to more-or-less known feedbacks, there might be others so far unimagined–something analogous to ‘top predator effects’, like the one in which we discovered that wolves can drive riverbank ecology and geology.
> https://www.google.com/search?q=+too+few+collisions+with+enough+energy+to+excite+the+greenhouse+gas+molecules
suggests to me this is more argued as political PR than quantum physics. The troposphere isn’t full of increasingly hot CO2 molecules surrounded by ‘room temperature’ nitrogen and oxygen molecules. It’s all the same temperature except for brief moments when something gets wound up enough to emit a photon, or absorbs a photon and gets wound up a bit more. Mostly they collide, and collisions aren’t quantized. Right?
This is probably the wrong place to resume this very old discussion that started at sci.env as far as I can recall, and that was 15 years or more ago. Footnotes are still lacking.
Hank,
I am surprised you have had to wait ten years for the answer to your question. It is that each of the greenhouse gases only absorbs in a band of the IR spectrum. There is also a band where there is no absorption (actually, ozone absorbs in its centre) called the infrared window. https://en.wikipedia.org/wiki/Infrared_window That window is used to measure surface temperatures by satellite.
Hank,
I wrote the the IR window is used to measure the surface temperature which I believe is true, but the satellite temperatures measured by Christy and Spencer, and the RSS measurements, are made using microwave not IR. However, those measurements are not the only ones which show a lack of warming in the upper troposphere. The radiosonde measurements do too!
Hank,
The link you provided was to a Google search results page. When I followed it the top hit was to your comment!
I assume you intended to provide a link to the second hit: https://wattsupwiththat.com/2011/03/29/visualizing-the-greenhouse-effect-molecules-and-photons/ and because it was a WUWT page you decided it was politically biased without reading it. In fact it is almost a correct description of the greenhouse mechanism. Compare that with this from Prof. Rabett: http://rabett.blogspot.co.uk/2009/08/getting-rudys-back-next-latest-issue-of.html?showComment=1252015297288#c3012501732548675340 which describes the same mechanism in more detail.
If you are going to ignore the result of my 15 years of research and persist on arguing about your interpretation of my initial thoughts, then not only is this the wrong place to discuss them, I have no desire to continue this discussion at all.
Alastair, that points out you’ve been talking about this many places for many years and I”m suggesting this isn’t a productive place to start yet another discussion, since earlier ones are so easy to find if you search for your phrase.
Re Tamino’s post on models, and “unforeseen” feedbacks:
Let’s not get bogged down too far in the semantics of a blog comment. There are plenty of areas for climate feedback where the range of possibilities is often contemplated (“foreseen”, if you will), but the actual future values within the range are hard to predict, or “foresee”. Don’t twist Tamino’s wording into something that is clearly dumber than Tamino would say, based on his long public record.
Hank,
If you would care to read my poster you would see that I am presenting new information, which was not available 10 and 15 years ago, e.g. Kennedy et al. (2012) and references therein.
See also Fig 5 in Santer, B. D., P. W. Thorne, L. Haimberger, K. E. Taylor, T. M. L. Wigley, J. R. Lanzante, S. Solomon, et al. ‘Consistency of Modelled and Observed Temperature Trends in the Tropical Troposphere’. International Journal of Climatology 28, no. 13 (15 November 2008): 1703–22. doi:10.1002/joc.1756. which shows that the models differ not just from the satellite data but also from the radiosonde data.
In my poster I explain why this is happening, which is directly related to this RealClimate thread.
In the past you have urged me to publish my ideas but then I did not have enough evidence. Now that I do, can’t you see that you are behaving like the cardinals who refused to look through Galileo’s telescope!
Alastair, #131–Alastair, according to the caption, Figure 5 is an experiment with synthetic data which shows that certain statistical tests do not work well. And the abstract of the paper contradicts what you claim in your comment. I don’t know what you are seeing, but what I see bears little relation to what you describe.
Alastair, your poster says:
You cite Santer et al.
That paper says:
I don’t see how that illustration from Santer et al. supports your argument, nor how their text supports it.
There’s been much written about the saturation argument you need to refute, I think.
https://www.google.com/search?q=site%3Arealclimate.org+saturated+gassy
Kevin, apologies – I meant Fig. 6 not 5.
In the abstract they claim that “Our results contradict a recent claim that all simulated temperature trends in the tropical troposphere and in tropical lapse rates are inconsistent with observations.”
But in the conclusion admit “We may never completely reconcile the divergent observational estimates of temperature changes in the tropical troposphere.”
Basically they “know” that the models are correct so of course they match the data. But this thread is yet another attempt to reconcile those differences.
To put it crudely, who do you believe? The climate modelling experts and 97% of scientists, or the little man at the back of the crowd who is asking “Why don’t the data and models agree?” Is it because the models are based on the wrong paradigm?
See A Paradigm Shift to an Old Scheme for Outgoing Longwave Radiation (OLR).
Hank, Thanks for reading and commenting on my poster.
As I explained to Kevin, I referenced the wrong figure in Santer et al. (2008).
The modellers are reluctant to admit that their models are wrong e.g. Santer et al (2008) but here is a partial acceptance from a more recent paper, Thorne et al (2011)
“Over the shorter satellite era, a discrepancy remains, particularly in the upper troposphere. Potential explanations range from the relatively uncontroversial involving residual observational errors (either at the surface or aloft), or statistical end-point effects, to more far-reaching reasons involving physical processes or forcings missing from some (known to be the case) or all climate models.
[Thorne, Peter W., Philip Brohan, Holly A. Titchner, Mark P. McCarthy, Steve C. Sherwood, Thomas C. Peterson, Leopold Haimberger, et al. 2011. ‘A Quantification of Uncertainties in Historical Tropical Tropospheric Temperature Trends from Radiosondes’. Journal of Geophysical Research: Atmospheres 116 (D12): D12116. doi:10.1029/2010JD015487.]
Even Ray Pierrehumbert admits that the saturation effect exist, only he claims it does not matter. But that is in a RealClimate blog. I have not seen that stated in a peer reviewed paper. Perhaps you know of one.
Questions:
1) If we are seeing the transition from what has been a strong el nino cycle back to a la nina by the end of the summer would it not be anticipated that in the short term the observational record will not be expected to catch up to modelled projections?
2) What ever happened to Michael Mann’s theory that the relative frequency of la nina to el ino events could itself be a feedback mechanism?
3) In regards to the suggestion prior by MM to converge on the most accurate models and the subsequent discussion of using a rational approach based on physical principals: (1) Is hindcasting not already a part of model creation in ways that lets statistical success drive forward projections? (2) should we not have models that are exclusively focused on projecting global temperature even if they poorly with other parameters? (3) What is a reasonable time period to let the effects of stochastic noise even out? Gavin previously claimed that a 20 year time period would likely suffice. I understand the argument that if you started 10 earths at the same time there would be significant variability in short term and even long term trajectories. However, if you added carbon dioxide to their atmospheres at the same rate to all 10 earths you would expect to be able to predict a range of possibilities that all 10 would fall within over a 20 yr period, particularly when the known natural “stochastic” variabilities happened historically over 10 year periods would you not? It seams to me to be a larger problem when the observations go out of the range of projections than when they do not correlate well to the mean.
4) Why has the climate change scientific community not moved on mass towards mitigation strategies? that would be the empirical approach given that carbon dioxide levels are continuously going up without any rational belief that this will change in the next 20 years.
I’m showing up a bit late to this party, but have some questions about problems not mentioned:
I.) Comparing like-to-like:
a.) also has the dimension that GCMs are from omniscient simulated worlds (the model knows its measurements perfectly) to limited keyhole views of pieces of the real world. Cowtan & Way pointed out that the most rapidly warming 1/7th of the globe is never captured in satellite or surface records; Karl pointed out that weighting issues affect ocean measures in 7/10’s of what is observed; satellites measure lower troposphere — and appear to do a very questionable job at that, with even RSS 4.0 in serious doubt and all of UAH up to 6.5 being shamefully inadequate.
b.) very few simulations are meant to simulate anything like what actually happened; how could they? GCMs cannot anticipate volcano, human activity or trade wind patterns in terms of exact start and end dates, though parameters for how much effect there is over the long term seem mostly adequate. Comparing those few models with parameters most like what actually evolved in reality — take Hansen 1988 Scenario B for example — we see remarkable fidelity in all but a few years, and those few years traceable to different volcano and trade wind actualities. That’s freakishly unexpected. 2016 has even exceeded Hansen 1988 B.
II.) Fitness to Purpose:
a) GCMs were prompted by the need to distinguish fingerprints of CO2 from other forcings, not especially to predict — emphatically in most cases to do nothing like predict — actual weather. For the original purpose, GCMs by and large have been successful, and improvements have come where expected by improving granularity and better parameterizations, eg for cloud, etc.
b) Satellite and surface weather stations have been improvised into global trend analyses, and are not well-designed to function as actual proxies for global temperature.
III.) What the heck, where is precipitation in all this? Why do we only bother with one of the 50 Essential Climate Variables GCMs could deliver?