Global climate
 Global climate statistics, such as the global mean temperature, provide good indicators as to how our global climate varies (e.g. see here). However, most people are not directly affected by global climate statistics. They care about the local climate; the temperature, rainfall and wind where they are. When you look at the impacts of a climate change or specific adaptations to a climate change, you often need to know how a global warming will affect the local climate.
Global climate statistics, such as the global mean temperature, provide good indicators as to how our global climate varies (e.g. see here). However, most people are not directly affected by global climate statistics. They care about the local climate; the temperature, rainfall and wind where they are. When you look at the impacts of a climate change or specific adaptations to a climate change, you often need to know how a global warming will affect the local climate.
Yet, whereas the global climate models (GCMs) tend to describe the global climate statistics reasonably well, they do not provide a representative description of the local climate. Regional climate models (RCMs) do a better job at representing climate on a smaller scale, but their spatial resolution is still fairly coarse compared to how the local climate may vary spatially in regions with complex terrain. This fact is not a general flaw of climate models, but just the climate models’ limitation. I will try to explain why this is below.
Regional climate characteristics
Most GCMs are able to provide a reasonable representation of regional climatic features such as ENSO, the NAO, the Hadley cell, the Trade winds and jets in the atmosphere. They also provide a realistic description of so-called teleconnection patterns, such as wave propagation in the atmosphere and the ocean. These phenomena, however, tend to have fairly large spatial scales, but when you get down to the very local scale, the GCMs are no longer appropriate.
Minimum scale
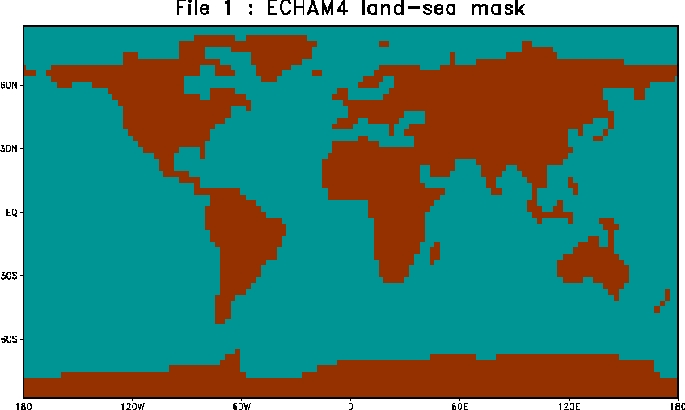 There are several reasons why GCMs do not provide a representative description of the local climate (i.e. exactly where I live). For one, the grid mesh, on which they compute the physical quantities relevant for the climate, is too coarse (typically 200km) to capture the local aspects. The figure on the left shows a typical land-sea mask for a GCM.
There are several reasons why GCMs do not provide a representative description of the local climate (i.e. exactly where I live). For one, the grid mesh, on which they compute the physical quantities relevant for the climate, is too coarse (typically 200km) to capture the local aspects. The figure on the left shows a typical land-sea mask for a GCM.
The distance between two grid points in a GCM (or an RCM) is the minimum scale (~200km). The coarse resolution typically used in the GCMs till now has implied that the topography has been smooth compared to the real landscape and that some countries (e.g. Denmark and Italy) are not represented in the models (one exception is one Japanese GCM with an extremely high spatial resolution).
Sub-grid processes are represented by parameterisation schemes describing their aggregated effect over a larger scale. These schemes are often referred to as ‘model physics’ but are really based on physics-inspired statistical models describing the mean quantity in the grid box, given relevant input parameters. The parameterisation schemes are usually based on empirical data (e.g. field measurements making in-situ observations), and a typical example of a parameterisation scheme is the representation of clouds.
Surface processes
 Climate models need boundary conditions describing the surface conditions (e.g. energy and moisture fluxes) in order to yield a realistic representation of the climate system. Often simple parameterisation schemes are employed to provide a reasonable description, but these do not capture the detailed variations associated with small spatial scales.
Climate models need boundary conditions describing the surface conditions (e.g. energy and moisture fluxes) in order to yield a realistic representation of the climate system. Often simple parameterisation schemes are employed to provide a reasonable description, but these do not capture the detailed variations associated with small spatial scales.
Skillful scale
Shortcomings associated with parameterisation schemes and coarse resolution explain why one gridpoint value provided by the GCMs may not be representative for the local climate. A concept called skillful scale has sometimes been employed in the literature, most of which have been linked to a study by Grotch and MacCracken (1991) who found model results to diverge as the spatial scale was reduced. Specifically, they observed that:
Although agreement of the average is a necessary condition for model validation, even when [global] averages agree perfectly, in practice, very large regional or pointwise differences can, and do, exist.
Although it is not entirely clear whether this study really touched upon skillful scale, it has since been cited by others, and used to argue that the skillful scale is about 8 gridpoints. Nevertheless, since the 1991-study, the GCMs have improved significantly, and the GCMs now are run for longer periods and with diurnal variations in the insolation.
Regionalisation


The figure above gives an illustration of the concept of regionalisation, or so-called downscaling. The left panel shows a typical RCM land-sea mask, giving a picture of its spatial resolution. The middle panel shows a blurred satellite image of Europe, which can illustrate how the sharp details are lost yet providing a realistic large-scale picture. The unblurred image of Europe is shown in the right panel. An analogy for the data from GCMs is looking at a blurred picture (middle above) while regional modeling (RCMs) and empirical-statistical downscaling (ESD) is putting on the glasses to improve the image sharpness (right above).
Both RCMs and GCMs give a somewhat ‘blurred’ picture albeit to different degrees of sharpness, and RCMs and GCMs are similar in many respects. However, GCMs are not just ‘blurred’ but also involve some more serious ‘structural differences’ such as an exaggerated Gibraltar Strait (see land-sea mask above), and the Great Lakes area, or Florida, Baja California are quite different and not just blurred (see figure below). Such structural differences are also present in RCMs (eg. fjords), but on much smaller spatial scales.
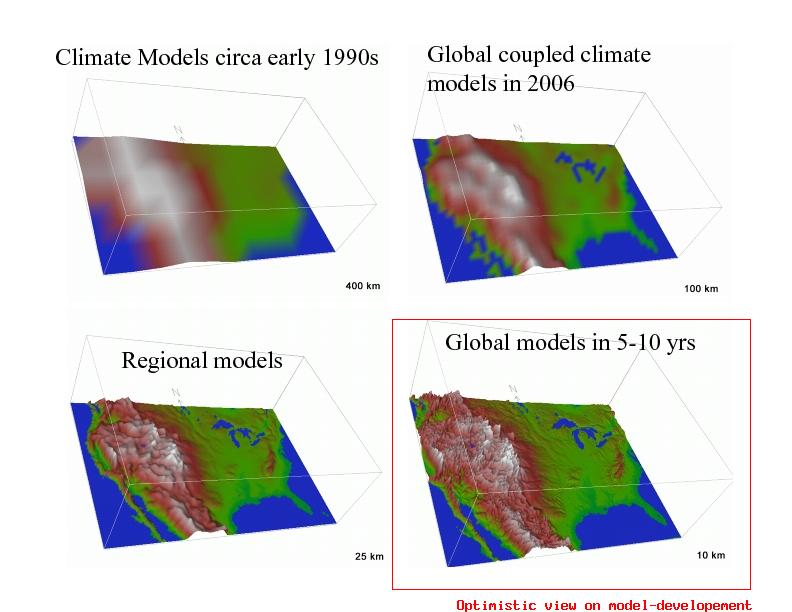 (Source: Strand, NCAR)
(Source: Strand, NCAR)Yet the images shown here for present climate models do not really show features down to kilometer scales that may influence the local climate where I live, such as valleys, lakes, mountains and fjords, even for RCMs (the lower right panel shows an optimistic projection for improved spatial resolution in GCMs for the near future). The climate in the fjords of Norway (can be be illustrated by the snowcover) is very different from the climate on the mountains separating them. In principle, ESD can be applied to any spatial scale, whereas the RCMs are limited by computer resources and the availability of boundary data.
What is the skilful scale now?
My question is whether the concept of a skillful scale based on old GCMs still apply for the state-of-the-art models. The IPCC AR4 doesn’t say much about skilful scale, but merely states that
Atmosphere-Ocean General Circulation Models cannot provide information at scales finer than their computational grid (typically of the order of 200 km) and processes at the unresolved scales are important. Providing information at finer scales can be achieved through using high resolution in dynamical models or empirical statistical downscaling.
The third assessment report (TAR) merely states that ‘The difficulty of simulating regional climate change is therefore evident’. The IPCC assessment report 4 (chapter 11) and the regionalisation therein will be discussed in a forthcoming post.
Any comments on this?
James C. McWilliams
Irreducible imprecision in atmospheric and oceanic simulations
PNAS | May 22, 2007 | vol. 104 | no. 21 | 8709-8713
http://www.pnas.org/cgi/content/full/104/21/8709
It emphasises that the problem is not just one of decreasing grid size.
What about the specific proposition that:
“No fundamentally reliable reduction of the size of the AOS dynamical system (i.e., a statistical mechanics analogous to the transition between molecular kinetics and fluid dynamics) is yet envisioned.”
Is this a problem of principle, like sensitive dependence on initial conditions, or something that enough years of hard work might crack?
Thanks Rasmus,
I did not fully grasp the concept of skilful scale. Are you saying that GCMs do not reliably represent climate to a resolution of 1 grid point and that to achieve accurate representation you need to average over about 8 grid points? Hence the “skilful scale” is 8 grid points.
[Response:This is basically the point, yes. But there has not been much discussion about what the skilful scale has been lately, so I’m not sure if it is still true. -rasmus]
Do climate scientists expect any surprises as resolution increases? Were there “surprises” between the 1980s GISS models and the latest models? I note that in our region (Australia) your minimum scale map leaves out Bass Strait (between Australia and Tasmania) and Torres Strait (between Australia and PNG). These are significant water ways for local climate and ocean currents. They are also about 150 km wide – close to 200 km – so why would they be omitted?
[Response:One Japanese model does have a very high spatial resolution, but I don’t think there are any particular surprises. Perhaps an improved resolution may provide a better rpresentation of the MJO and the monsoon system as well as cyclones. The very high resolution model makes very realistic pictures of the cloud and storm systems, and the guys presenting the results are fond of showing animations which look very much like satellite pictures. Quite impressive. -rasmus]
Do GCMs capture coarse topographic features, eg the Tibetan Plateau?
[Response:apparently not well enough. -rasmus]
I agree that for quantitative studies GCMs cannot be used at a regional or single gridpoint scale. However, the results can be considered valid at a qualititave level.
[Response:I think this is true too, but downscaling should in general add value to the simulations. -rasmus]
I have used a VERY coarse resolution GCM (8 degrees by 10 degrees) to help plan a vacation, and it worked quite well. The data provided by the GCM was better than any guide book or even the CIA World Factbook. In addition, the GCM provided more than just temp + precip, including other useful variables like cloud cover (tanning), soil moisture and ground wetness (camping) and wind speed and direction (windsurfing).
See my EdGCM writeup on my vacation planning for more details: http://edgcm.columbia.edu/outreach/showcase/cambodia.html
It would be helpful to provide a useful definition of what is meant by “local”.
No, no, no. Why doesn’t the AUTHOR OF THE ARTICLE give a useful definition of LOCAL climate!
What is meant by LOCAL climate?
[Response:I’m getting the message, don’t worry. To me, the local climate is the climatic characteristics which have are directly relevant to my perceptions. This would normally be on a smaller scale than a grid-box for a GCM and smaller than ‘meso scales‘ referred to in meteorology (more like ‘meso-gamma‘) and smaller than minimum scale of most RCMs (which typically have spatial scales of ~50km, although some go down to ~10km). I define regional scales as somewhat larger, that whch characterises a larger region (e.g. at meso scale to synoptic scales). -rasmus]
How do you manage to convert heat, as in watts m-2, into temperature?
What is the relationship between the steady state input of energy, in watt m2, and total global atmospheric volume, pressure and temperature?
[Response:First law of thermodynamics, but this is done in the models. -rasmus]
Thanks for this post.
You say:
“Most GCMs are able to provide a reasonable representation of regional climatic features such as ENSO, the NAO, the Hadley cell, the Trade winds and jets in the atmosphere. They also provide a realistic description of so-called teleconnection patterns, such as wave propagation in the atmosphere and the ocean.”
I would like to know, given that these (and other) regional features have not been studied all that long, how stable they are, in the mathematical sense of the term.
A second question is: what do you mean by “*reasonable* representation”? Any links to the primary literature on either question would be appreciated.
Thanks again. I look forward to more on the topic of how GCMs are constructed and parameterised.
P.S. There are a couple of typos in the article: aggrigated, parametereisation
re #5: “local” is an intentionally flexible concept. Often sub-continental, sometimes smaller, somewhere between 100 and 1000 miles.
[Response:The best link is probably to the IPCC AR4 chapter 8. -rasmus]
There are distributed computing projects for SETI, protein folding, and crypto cracking … but none for global climate change? OK, I’ve Googled after writing that line and I find http://ClimatePrediction.Net … but I don’t have the skill to determine if what they’re doing is valid or not.
What doesn’t RealClimate have a distributed computing initiative? This place certainly has the pull to get people interested in providing computing power.
And thusly (and quite tangentially) the model resolution could improve.
[Response:Climateprediction.net is a SETI-inspired initiative where GCMs are run as screen-savers. These GCMs are coarser than the ‘normal’ GCM run on super-computers, but the vast number of runs provide high ‘statistical power’ (a very large ensemble yields a large statistical sample). I don’t know of any initiative where distributed computing has been used to for one high-resolution GCM (i.e. splitting the world into managable chunks of computation), and I think that would be very unpractible as this requires a high rate of data exchange. -rasmus]
Thanks for this post. You say:
“Most GCMs are able to provide a reasonable representation of regional climatic features such as ENSO, the NAO, the Hadley cell, the Trade winds and jets in the atmosphere. They also provide a realistic description of so-called teleconnection patterns, such as wave propagation in the atmosphere and the ocean.”
I would like to know, given that these (and other) regional features have not been studied all that long, how stable they are, in the mathematical sense of the term. A second question is: what do you mean by “*reasonable* representation”? Any links to the primary literature on either question would be appreciated.
Don’t some of the GCMs (e.g. NCAR’s CCSM3) try to address coarse grids by having models for different terrain within the grids, and then weighting them according to their area for the grid cell? Does this not help things?
You don’t say much about what “skilful scale” means. Is this the same as some other supercomputer techniques when the grid size is not constant but instead varies as needed?
[Response:I don’t think the literature is very clear on this (try googeling ‘skilful scale’; I only got 20 hits!), and I thought it would be interesting to bring it up in this forum. -rasmus]
Re #5: “local” is an intentionally flexible concept, something smaller in scale than “regional”. The author defines this term in the opening paragraph in human terms, as the spatial extent over which most of us live most of our lives. Seems to me he’s talking about something the size of a state or smaller. Doesn’t much matter, as his point is that GCMs don’t work well at those small scales. Hence the attempt to define the minimum scale over which the models are skillful. “Local” is therefore anything smaller than that.
Thank you for the great job of this site.
I’ve got a question somewhat related to this article. You gave insights on the spatial resolution of the climate models. I am wondering what you can say on their temporal resolution. More precisely, climate models are predicting the mean temperature evolution. Are there any precision on the evolution of the thermal amplitudes, and on what time scale?
Thank you again.
G. Gay
[Response:One important consideration is the size of the model’s time-step (order of minutes), and then the type of time-stepping (integration) scheme matters. But I’m not sure what the exact answer is to this (others?). -rasmus]
Re #6: [There are distributed computing projects for SETI, protein folding, and crypto cracking…]
This comes down to a fundamental difference in computational methods. The problems you mention can be broken down into many computationally independent pieces. Each of the pieces can be worked on independently, and the results collected and combined whenever they’re done.
Climate models (and many other problems) work on a grid. At each timestep, values are computed within each cell. Those computations depend on the values of the previous timestep, and the values in adjacent cells. That means there’s a lot of data exchange going on. This might happen in memory on a single processor machine (very fast), or via a dedicated high-speed network on a parallel machine (e.g. IBM BlueGene). But if you tried to do this over the internet, the communication time would be very much larger than the time needed to do the computations themselves.
I have been interested in the regional and local climate changes partially because as Rasmus writes that is what effects people’s daily lives, but also because regional and climate changes will need to be better predicted to determine the ecological changes caused by climate change.
Are there any barriers that prevent better regional and local climate predictions? For example are there problems in regional vs global models like the difference between climate and weather prediction (ie weather is chaotic and therefore less predictable than climate) that make it impossible to make better local/regional predictions, or is it just a question of researching more and developing better models?
[Response:Good question. I suppose in theory, one could always go down in scale, and when taking it to the extreme, to the scale of atoms (quantum physics). At one point, I expect the downscaling will becom impractical, at least. -rasmus]
Google: climate distributed computing
First two Results of about 1,130,000 for climate distributed computing. (0.20 seconds)
BBC – Science & Nature – Climate Change …experiment used a technique called distributed computing to utilise users’ spare computing power to predict future climate. http://www.bbc.co.uk/sn/climateexperiment/theexperiment/distributedcomputing.shtml
Distributed computing tackles climate change. Posted by Stephen Shankland. Oxford University and the BBC have launched a partnership …. news.com.com/8301-10784_3-6041683-7.html
re: #6
#10 is right, but in addition:
The problems for which @home distribution works have some other characteristics as well:
EITHER:
1) There are a large number of independent input cases, each of which can be analyzed separately, using a modest amount of input, and yielding a simple answer that is easy to verify:
a) YES/NO (“hello Earth. Why aren’t you answering us?”
or INTERESTING/NOTINTERSTING, as particle physicists have long done, i.e., send an event to each free machine, have it crunch for a while, and say whether or not something interesting happened worth further analysis.
b) A few numbers, as in crypto-cracking: “here are the prime factors”, which make take a long time to find, but are trivial to verify by multiplying them back together.
c) A number, which is mainly of interest if it’s the bet found so far, i.e., as in Monte Carlo approaches to protein folding or Traveling Salesman routing problems.
OR
2) One is doing a Monte Carlo simulation where there is no right answer, but one is interested in generating an ensemble of results, and analyzing the distribution, i.e., “Do you have enough money to retire?” A delightful short piece on such is Sam Savage’s “The Flaw of Averages”: http://www.stanford.edu/~savage/flaw/
I think the ClimatePrediction.net effort is of this sort, and it may be useful, but it doesn’t help the topic discussed in the (nice) original posting.
Note that going from a 100km grid to a 10km grid means a 10×10 = 100X more elements (2D), and if it were general 3D, that would be 1000X. In many disciplines, people using such methods have had to do non-uniform-sized subgridding to improve results with a given level of computing. I.e., for some parts of a model, a coarse grid gives reasonable results, but for others, one needs a much finer grid.
This is all very interesting but as far as I’m concerned fails to give an accurate enough picture of the processes at work behind the differences in predictions.
What I would like to see is a much more detailed run-through of the differences in local predictions by models and concurrently, the unique ways in which they simulate natural processes.
If 8 grid points represents a skillful representation and 1 does not, can you give a relevant example of how regional dynamics cancel each other out at that scale?
[Response:I don’t think it’s necessary a matter of ‘cancelling out’ but rather giving a ‘blurred’ picture or for instance a spurious geographical shift of a few grid points due to e.g. approximations of local grid-point scale spatial gradients. -rasmus]
I am running a distributed model for climateprediction.net. I would just as happily run one for realclimate. I am not a scientist and real climate has given me the insight and the links to further education which enable me to refute the flat earth rightwingers on the political board I frequent. They are no longer as dismissive and abusive as they were two years ago, when I began studying the information on your website. Thanks and if you need some of my cpu cycles, I will be glad to donate.
[Response: Watch this space… – gavin]
I’m curious about this example of a regional-local prediction:
Model Projections of an Imminent Transition to a More Arid Climate in Southwestern North America, Seager et al. Science 2007
Abstract: “How anthropogenic climate change will impact hydroclimate in the arid regions of Southwestern North America has implications for the allocation of water resources and the course of regional development. Here we show that there is a broad consensus amongst climate models that this region will dry significantly in the 21st century and that the transition to a more arid climate should already be underway. If these models are correct, the levels of aridity of the recent multiyear drought, or the Dust Bowl and 1950s droughts, will, within the coming years to decades, become the new climatology of the American Southwest.”
This is within the ‘skillful scale’. However, if one wants to know the effect on California’s Central Valley (an area of massive agricultural production) and on Sierra Nevada snowpack levels, it seems the models still lag behind the observations – but water districts should probably be focusing on long-term conservation strategies right now.
This paper, based on observations, seems to provide support for Seager et al :Summertime Moisture Divergence over The Southwestern US and Northwestern Mexico, Anderson et al GRL 2001
They note that moisture divergence over the American Southwest increased in 1994, in line with model predictions of persistent drought.
Droughts are a common feature of the ‘unperturbed climate system’ but this change appears attributable to anthropogenic climate change. Seager et al report that the persistent drying is due to increased humidity, which is changing atmospheric circulation patterns and leading to a poleward expansion of the subtropical dry zones. Increases in atmospheric humidity are a long-standing prediction of the effects of increased anthropogenic greenhouse forcing.
Surely very high resolution experiments were done on smaller time scales covering wide regions, wasn’t there any significant change in results?
Local drying would be good to predict for urban planning; for example can Las Vegas USA or Adelaide Australia sustain their current populations? A year or two ago AGW was interpreted as ‘wetter everywhere’ but now that doesn’t seem to be the case.
How do you manage to convert heat, as in watts m-2, into temperature?
What is the relationship between the steady state input of energy, in watt m2, and total global atmospheric volume, pressure and temperature?
[Response:First law of thermodynamics, but this is done in the models. -rasmus]
Is that sarcasm?
How do you calculate the amount of heat in the atmosphere, in terms of volume, pressure and temperature ?
[Response:You can use the ideal gas laws or the radiative balance models, depending on the situation. Besides, you may in some cases need to consider the latent heat associated with vapour concentrations and the condensation processes. But I’m not sure that I understand your point. -rasmus]
Re: Climate versus weather
One way of thinking about the results of a climate model is that “climate is what you expect, weather is what you get.”
Consider a simple box-model for the Earth: heat goes in, heat goes out. There’s only one number for temperature, and that spans the “grid” of the entire Earth. Everything else, like the difference between Nunavut and Napa Valley, would be “weather” to the model.
As computer models become better, we can see more detail, both in time and space. Parts of “classical” climate, like the ENSO, start showing up accurately — but this would still be “weather” to the whole-Earth-box.
If we had a superfine model, that simulated at whatever timestep and resolution you wanted to name, then we’d be able to refine the definitions. Climate would be what happens over an ensemble of initial conditions, and weather would be what happens if you plug in conditions as-of-now. Until that point, we have to look at averages over both initial conditions and over insufficient resolution.
Re: Distributed climate models
Unfortunately, climate models are just plain big. The Earth is a big place by itself, and a research-quality climate model needs a relatively fine resolution over the surface.
Even though they’re physically separated, different parts of the Earth also affect each other, climate-wise. In terms of weather, just consider the “butterfly effect.” It’s still present in average climate, albeit (generally) less pronounced.
Combine both of these points, and you have a lot of data (for the globe) that depends on the entire lot of it at prior times. This sort of communication is what distributed systems like SETI@Home are really bad at. That’s why full-resolution climate models are most suited for a single supercomputer or a cluster of tightly-connected machines.
That’s not to say that there’s nothing left for researchers without massive computer budgets. As the article hinted at, there’s a lot of work done in the “subgrid-scale” modelling. That encompasses most of the physics that actually happen, only on a physical scale that would be otherwise invisible to the global model. They’ll never be perfect (because they’re estimated, rather than directly simulated), but improving those models would go a long way to helping the accuracy of global climate models.
[[How do you manage to convert heat, as in watts m-2, into temperature?
What is the relationship between the steady state input of energy, in watt m2, and total global atmospheric volume, pressure and temperature?
[Response:First law of thermodynamics, but this is done in the models. -rasmus]]]
Don’t forget the ideal gas law.
Do you have any evidence that the Earths air pressure and volume has remained constant over the last 200 years?
Do you have any evidence that the Earths atmosphere has the same water content over the last 200 years ?
How do you calculate virtual heat, along the atmospheres vertical axis, give the large chages in air temperature and pressure, when you convert from a non-ideal gas when applying the ideal gas law ?
[Response:You mean, do I have any evidence that the mass of Earth’s atmosphere has changed over the last 200 years (the sea level pressure provides a measure of the air masses above and I’m presuming you are not suggesting that Earth’s gravity, i.e. that that Earth’s mass has changed appreciably)? What do you mean by ‘the air volume’. The atmospheric extent? This is irrelevant if you are looking at the air property in a unit volume (m^3). I still don’t get your point; how is this relevant to the GCMs ability to describe small-scale climatic features? -rasmus]
This scale problem is mirrored in many other disciplines. In transportation modelling, for example, we can run very general models with just a few well-understood parameters, and get results that are generally reasonable matches with observations. So many households, workers etc gives so many trips in a day within a region.
As we move to increasingly disaggregated models (finer scale) we have to consider more detailed parameters (about which we have progressively less confidence as we strive for finer detail) and we produce increasingly more detailed outputs which look very plausible, but which have a progressively higher chance of giving the wrong answer about what is going on in the street outside your house at dinner time on Thursday.
At the end of the model re-fining process we are trying to observe electrons, for which (it seems) we can either know one state or another, but not both at the same time.
Im sure the climatologists are aware of this. Its easy to produce a fancy model that looks good, but as the level of detail increases the rubbish-in-rubbish-out factor increases significantly. Its better to run with a robust broad-scale model, and apply common sense to the interpretation of sub-regional effects, than to run a rubbishy micro-model that cannot be shown to be exactly true anyplace at any given time.
It�s a matter of confidence, and understanding. If you cannot mentally get you head around the input parameters with a high level of understanding and confidence, then its very hard to defend the results. Take it easy.
Besides, we really do know all we need to know already, dont we. Whether its going to rain at your place on 1 July or not makes no difference to the main conclusions. Its going to get hotter, the ice is going to melt, the sea is going to rise – even if we can hit 2050 emission targets. The horse has bolted for the hills, all we can do is figure out how to run after it!
>Earth’s air pressure
Torricelli
See “expansion tectonics” or “expanding Earth” for the argument that the Earth’s air pressure has changed — along with its mass, and diameter. It’s a religious alternative to geology.
Nigel Williams (#28) wrote:
Oh, I am not sure you want to compare this to transportation modeling – or at least not highway performance modeling.
In forecasting future traffic patterns with increased populations, traffic modellers fall back on a formula which works quite well except in periods of high congestion – exactly where you would want to have it work the best – assuming you are concerned with vehicle hours of delay or the ratio of freeflow speed versus projected actual speed. The problem is that they calculate speed as a function of volume (vehicles per hour passing a given point). In high congestion, there is a point you hit where the volume will remain constant but the speed drops by several factors for several hours. When congestion finally begins to fall, volume will remain constant with speed gradually rising until a point is hit at which traffic volume begins to fall and a one-to-one relationship between volume and speed is reestablished.
Additionally, if anyone does the post-processing other than the modellers, you might want to be sure that they know how to properly calculate normalized performance measures. In my state, the fellow who implemented those calculations was under the impression that the averages were largely subjective – which didn’t help any. For example, he did a weighted averaging of speed by vehicle miles.
In case some don’t the problem with this, imagine that you are dealing with just a single car where there are two legs to given trip. In the first leg, the car travels 50 mph for one hour, then in the second it travels 10 mph for 5 hrs. Using his weighted averaging, the car’s average speed is 30 mph. However, the car has travelled 100 mph in 6 hrs, giving a real average speed of 16.67 mph.
Thanks to their unusual way of doing math, by the time you aggregated by both time and location, all but one out of over a hundred performance measures were wrong. The only thing they were calculating correctly was length of highway. Even the lane-mile calculations were off: they were calculating it as the maximum of the two directions.
I came in as a temp programmer, identified the problem with their calculations and then reworked the functions. (The rule is to always calculate in aggregates at each level of aggregation, then at the very last step calculate the normalized measures as simple functions of the aggregates – generally through addition and division.) Incidently, I didn’t have any background in the area, either. But I noticed the inconsistencies – and then thought about it. It was clear, for example, that average speed had to be vehicle miles over vehicle hours, and after that the rest started to fall into place. The rework made quite a difference: all of the sudden they could see the congestion in the urban areas at the aggregate level – and the rural areas were looking far better.
Re #27: [Do you have any evidence that the Earths air pressure and volume has remained constant over the last 200 years?]
The first barometers were invented in the 1700s (or maybe even earlier?) Certainly by the mid-1800s they were extremely sensitive. Not long ago I was reading a book about the erruption of Krakatoa (the title of which I’ve forgotten, alas), which described how recording barometers around the world detected air pressure waves from the explosion for many days afterwards.
Then there’s all sorts of indirect evidence, as for instance gas laws & conservation of mass: you seem to be suggesting that the actual amount of atmosphere might somehow have changed. If so, then where did it come from/go to?
O.K. I will make it very simple, adding heat to the atmosphere can change the temperature, the pressure and the volume.
When the model an increase in the amount of heat in the atmosphere, what is the relationship bettwen heat input and temperature, pressure and volume?
Secondly, have you manages to observe changes in the volume or pressure of the atmosphere; do thses changes match your models?
Finally, finally, how can you model using the ideal gas law, when the atmosphere is a mixture of gasses, some of which do not follow the ideal gas law even when studied in isolation, much less mixtures?
[Response:The pressure is more or less given in this case by the mass of the atmosphere above the point of interest. However, if you say that the air expands so much (due to an increase in the temperature) that the gravitational forces are reduced for the top of the atmosphere, then possibly there may be an effect. But keep in mind that the atmoshpere is in essence already a very thin shell of gas anyway. I guess this effect would be very minor, if at all noticable. Exactly which gases do not follow the ideal gas law? -rasmus]
I appreciate the link to Chapter 8, and likely could learn much at that website. Reading the author r‘s development here on RC, I thought some fractal math could provide a differential layer for drilling into the overarching model’s output, or, rather, could form the granular infrastructure from which base the model could grow, topologically placing the GCM layer as the outer, visible depiction for the fractally defined substrate. But all this probably is in the math literature for the climate-weather models in existence.
Thanks to their unusual way of doing math, by the time you aggregated by both time and location, all but one out of over a hundred performance measures were wrong. The only thing they were calculating correctly was length of highway. Even the lane-mile calculations were off: they were calculating it as the maximum of the two directions.
That’s not to say that there’s nothing left for researchers without massive computer budgets. As the article hinted at, there’s a lot of work done in the “subgrid-scale” modelling. That encompasses most of the physics that actually happen, only on a physical scale that would be otherwise invisible to the global model.
anyway,Thank u very much for your sharing
#32 Atmosphere modelling
Doc, like some others here I am puzzled as to what you’re trying to say.
If all relevant physical (gas) laws are in the GCMs (which they no doubt are), I suppose that these must be some pressure / volume change in the atmosphere if you heat it (probably small, for example 1 deg heating would give 0.3% volume change if pressure is constant). But this does not seem to be very important if we are interested in temperature (which can be verified directly against measurements).
And it seems to me that at pressures of 1 bar max the ideal gas law (PV=RT) is perfectly adequate for the problem at hand.
“The pressure is more or less given in this case by the mass of the atmosphere above the point of interest. However, if you say that the air expands so much (due to an increase in the temperature) that the gravitational forces are reduced for the top of the atmosphere, then possibly there may be an effect.”
The composition of gas in the vertical cross section of the atmosphere depends on the absolute T and the molecular weight of the gas. It should also be apparent that the atmosphere is “V” shaped, any expansion of the atmosphere (in response to an increase in energy) could have a disproportionate effect on pressure. I have a little sketch calculation looking at what would happen in terms of volume, pressure and temperature of an idealized atmosphere, without water vapor, and found it was very hard to do. I ended up with a system that was rather like a ballon, you can add heat into it and it inflates as the pressure increases. So does the atmosphere act like a ballon? Does it expand and pressurize when you add heat into it in your models?
Another point if it does expand, its surface are should increase and so its radiation into space should also increase.
‘Exactly which gases do not follow the ideal gas law?”
The only gases that follow the ideal gas laws are monoatomic (uniatomic), He, Ne e.t.c. Both di and biatomic gases lose (at least) one degree of freedon along an axis, and triatomic gases like CO2 behave with a large degree of non-ideal character.
The people who really know about this stuff are into air conditioning and refidgeration, the basics is here:-
http://www.zanderuk.com/tech_Centre.asp?chapter=1§ion=2_Compression_3.htm&getIndex=false
there quantum mechanics of simple triatomic gases, like CO2, has also been explored (but is way over my head) and is a little odd to say the least.
On a practical level the ratio of the constant-volume and constant-pressure heat capacities, CV and CP, depends on the degree of freedom and is different in mono,bi and triatmic gases.
http://www.whfreeman.com/college/pdfs/halpernpdfs/part04.pdf
The real problem is that gamma can change at phase transitions, the real fly in the ointment must be the modeling CV/CP ratios at, or near dew points.
So just how do you manage to model it?
[Response:We are not talking about airconditioners and compression in the case of the atmosphere, and most of the atmosphere consists of gases with biatomic molecule s. CO2 is a trace gas with ~380 parts per million in volume (ppm), and doesn’t play a big role in terms of volume and pressure (it’s more important when it comes to radiative properties). So, as far as I know, the ideal gas laws still provide a good approximation to the atmosphere’s behaviour. It seems to work for numerical weather models used in daily weather forecasts :-) -rasmus]
JohnLopresti (#33) wrote:
I at least know they have been thinking something along those lines…
… for a while…
Likewise, when it comes to simulating the evolution of past climates, they will use slightly pink noise in the proxies, although it is much closer to white noise – about 15% red or less, if I remember correctly, where red noise would be the 1/f scale-free variety, similar to that found in music and falling rain. This was brought up in a guest commentary not too long ago:
24 May 2006
How Red are my Proxies?
Guest commentary by David Ritson
https://www.realclimate.org/index.php/archives/2006/05/how-red-are-my-proxies
Pink noise realistically mimics the actual noise found in the record, I believe.
Timothy, your …all but one of over one hundred performace measures were wrong.. comment supports my point. You can make simple models work well and give reasonable answers within their scope, but as the number of parameters increases then the chances of the inputs and hence the outputs being wrong in detail increases. So we start being able to speak quite confidently about one thing, and in the end we are able to say nothing certain at all about absolutely everything. Nuf said.
#32 and #35. If 0.3% is the expected change in atmospheric pressure for each degree change then it would not be minor and it should be measurable.
This is an excellent overview of the technology and its limitations. I will suggest that my readers on my site (http://www.globalwarming-factorfiction.com) jump over here to read this. I have been trying to explain the limitations of climate modeling piece by piece for some time and this article does a great job of explaining the entire spectrum.
I agree with others that have commented that it would be great to have a SETI type distributed process. I understand that the current implementations of this type of project minimize some of that advantage but the SETI techniques are quite old and distributed computing algorithms have evolved quite a bit over the last 3-5 years. If NOAA (or another government agency) would put some effort in this area, I think we would be suprised. Perhaps a campaign to write our elected officials to fund that might make sense. I may do this on my site if I can figure out the details.
Wait. Adding heat to air makes it heavier?
What’s the source for “0.3% is the expected change in atmospheric pressure for each degree change”?
Re#27&31. These comments haven’t been adequately answered.
The question concerns whether the mass of the atmosphere has been conserved over a 200 year timeframe. It obviously hasn’t over geological history but that is not relevant here. How sensitive is temperature to pressure and I assume that at ca. 1 bar+/- 0.1 bar the atmosphere behaves ideally as noted PV=nRT.
The adiabatic lapse rates are considerable-
http://commons.wikimedia.org/wiki/Image:795px-Emagram.gif Were The mass of the atmosphere 10% greater at sea level ie. 110kPa one would extrapolate mean temperatures ca. 8 celsius higher than at present.
A direct empirical observation would be the mean temperature regime along the Dead Sea, well below present sea level.
As temperatures rise the oceans and soils will degass according to Henry’s Law and atmospheric pressure will arise not solely because of PVT but also because the mass of the atmosphere is no longer conserved.
I presume that climate models assume only that the mass of the atmosphere is conserved over centuries, ie. ca.5.1*10exp21g and this mass doesn’t change upon degassing.
Would a butterfly flapping its wings make a model diverge to the point of being useless. that is, a model really can’t go down too small unless there is both computing power and data that would make the model somewhat accurate.
Paul M. (#38) wrote:
Seek and ye shall find…
I used the website’s search engine, but I had seen it before.
DocMartyn,
A debating hint: Condescencion is usually much more effective when one has a clue what one is talking about. To a first approximation, most gases behave as ideal gases, so any effects would be 2nd order. And yes, I would expect that the atmosphere does indeed expand due to increasing temperature–you’d expect this just from the fact that the molecules have increased energy. However, the atmosphere does not heat equally, and I’m really don’t see what it has to do with the subject at hand–or much of anything else. As to temperature vs. radiation field, see
http://en.wikipedia.org/wiki/Stefan-Boltzmann_Law
and
http://en.wikipedia.org/wiki/Albedo
Please, keep in mind that the earth’s atmosphere is NOT in a sealed container. In 1998 when solar heating dramatically warmed the upper atmosphere, the atmosphere expanded and the result was an increase in the drag on orbiting satellites. Solar flares and other events are known to cause changes in the upper atmosphere that affect the thickness of the atmosphere. This has been fairly well studied as satellites require more effort to maintain orbit when solar activity increases.
My guess is that what should be looked at, rather than pressure, is density. I’m sure that PV = nRT hasn’t been repealed just yet …
Re #38 Higher model resolution and better data on initial conditions do not solve the problem of chaos (sensitivity to small changes in initial conditions) in weather models, if that’s what you’re asking. As far as the climate models go, chaos in the time domain is not the issue – not for something like a global mean, anyways. What is an issue is the related problem of structural instability, which is sensitivity of model output to small changes in model formulation. i.e. Switch one flavor of module for another, say, better one, and there is no guarantee the new ensemble will behave in a predictable manner, let alone better. Not only will the output change metrically, but it will also change topologically. That means that entirely new circulatory features (ENSO, PDO, NAO, etc.) could emerge from the model as a result of highly altered attractor geometry. Same butterfly, totally different impact, all because of a change in one module. If these changes are deemed unacceptable by the modeler then the model will presumably need to be recalibrated by tuning the free parameters available from the non-physics-based portion of the model.
Of course this explanation comes from a non-expert, so I would pass it by someone more qualified before taking any of it on faith.
If you are trying to assert that butterflies can’t alter the global circulation, then I would ask for some hard proof of that assertion. Those that argue that “weather is chaotic, climate is not” would probably agree with you, but then again I’m not sure they’ve really made their case. If I’m wrong I would be happy to review some material from the primary literature. After all, we haven’t been observing the global circulation all that long. How do we know empirically which circulatory features are stable and which are unstable?
#41 Hank
0.3% just follows from the gas law pV=RT. If T goes from 288 (Earth temperature) to 289 K and p=C, then V must necessarily increase by 1/288 = 0.3%.
Of course it’s more complicated than that (for example: the atmosphere does not heat uniformly, and is colder the higher you go, etc), but this was just to show that atmospheric expansion is probably not a big deal.
Thanks for this explanation. The way I describe the problems of resolution to the lay person is to relate it to the result of a football match. If Celtic (top of the SPL this season) were to play East Stirling (bottom of the 3rd division)we could all predict the result with some confidence. That’s where I guess GCMs are right now. Some experts might want to hazard the more difficult task of predicting the score. That I guess is where decadal regional models would like to be. But if anyone said that they could forecast not only the score, but also the scorer and the time of each goal with confidence then we’d all say they were nuts.
From the text above: “We were hoping for important revelations and final proof that we have all been hornswoggled by the climate Illuminati”
As a climate scepticus I’d like to comment that it is never “conspiracy” that we suspect to lay at the basis of the CO2-hype.
It is a time spirit working here, one of rebellion against the industrial revolution, a romantic longing to a virgin world, that brings people to target our capitalist consumption society.
A time spirit, not a conspiracy.