We hold these truths to be self-evident, that all models are created equal, that they are endowed by their Creators with certain unalienable Rights, that among these are a DOI, Runability and Inclusion in the CMIP ensemble mean.
Well, not quite. But it is Independence Day in the US, and coincidentally there is a new discussion paper (Abramowitz et al) (direct link) posted on model independence just posted at Earth System Dynamics.
What does anyone mean by model independence? In the international coordinated efforts to assess climate model skill (such as the Coupled Model Intercomparison Project), multiple groups from around the world submit their model results from specified experiments to a joint archive. The basic idea is that if different models from different groups agree on a result, then that result is likely to be robust based on the (shared) fundamental understanding of the climate system despite the structural uncertainty in modeling the climate. But there are two very obvious ways in which this ideal is not met in practice.
First, if the models are actually the same, then it’s totally unsurprising that a result might be common between them. One of the two models would be redundant and add nothing to our knowledge of structural uncertainties.
Second, the models might well be totally independent in formulation, history and usage, but the two models share a common, but fallacious, assumption about the real world. Then a common result might reflect that shared error, and not reflect anything about the real world at all.
These two issues are also closely tied to the problem of model selection. Given an ensemble of models, that have varied levels of skill across any number of metrics, is there a subset or weighting of models that could be expected to give the most skillful predictions? And if so, how would you demonstrate that?
These problems have been considered (within the climate realm) since the beginnings of the “MIP” process in the 1990s, but they are (perhaps surprisingly) very tough to deal with.
Ensemble Skill
One of the most interesting things about the MIP ensembles is that the mean of all the models generally has higher skill than any individual model. This is illustrated in the graphic from Reichler and Kim, (2008). Each dot is a model, with the ensemble mean in black, and an RMS score (across a range of metrics) increasing left to right, so that the most skillful models or means are those furthest to the left.
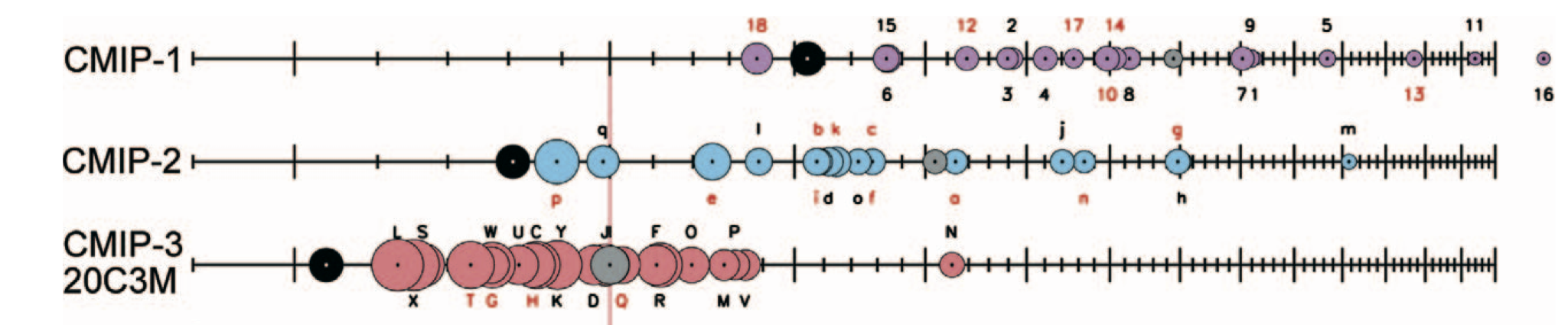
But as Reto Knutti and colleagues have showed, the increase in skill of the ensemble mean doesn’t keep increasing as you add more models. After you’ve averaged 10 or 15 models, the skill no longer improves. This is not what you would expect if every model result was an unbiased independent estimate of the true climate. But since the models are neither unbiased, nor independent, the fact that there is any increase in skill after averaging is more surprising!
One Model, One Vote
The default approach to the ensemble (used almost uniformly in the IPCC reports for instance), is the notion of “model democracy”. Each model is weighted equally to all the others. While no-one thinks this is optimal, no-one has really been able to articulate a robust reasoning that would give a general method that’s better. Obviously, if two models are basically the same but have different names (which happened in CMIP5), such an ensemble would be wrongly (but only slightly) biased. But how different would two models need to be to be worthy of inclusion? What about models from a single modeling group that are just ‘variations on a theme’? They might provide a good test of a specific sensitivity, but would they be different ‘enough’ to warrant inclusion in the bigger ensemble?
Model selection has however been applied in hundreds of papers based on the CMIP5/CMIP3 ensemble. Generally speaking, authors have selected a metric that they feel is important for their topic, picked an arbitrary threshold for sufficient skill and produced a constrained projection based on a subset or weighted mean of the models. Almost invariably though, the constrained projection is very similar to the projection from the full ensemble. The key missing element is that people don’t often check to see whether the skill metric that is being used has any relationship to the quantity being predicted. If it is unrelated, then the sub-selection of models will very likely span the same range as the full ensemble.
The one case where model selection was used in AR5 was for the Arctic sea ice projections (based on Massonnet et al, 2012) where it is relatively easily demonstrated that the trends in sea ice are a function of how much sea ice you start with. This clarity has been surprisingly difficult to replicate in other studies though.
So what should we do? This topic was the subject of a workshop last year in Boulder, and the new ESD paper is a partial reflection of that discussion. There is a video presentation of some of these issues from Gab Abramowitz at the Aspen Global Change Institute that is worth viewing.
Unfortunately, we have not solved this problem, but maybe this paper and associated discussions can raise awareness of the issues.
In the meantime, a joint declaration of some sort is probably a little optimistic…
We, therefore, the Representatives of the united Modelling Groups of the World, in AGU Congress, Assembled, appealing to the Supreme Judge of the model ensemble for the rectitude of our intentions, do, in the Name, and by Authority of the good People of these modeling Centers, solemnly publish and declare, That these disparate Models are, and of Right ought to be Free and Independent Codes, that they are Absolved from all Allegiance to NCAR, GFDL and Arakawa, and that all algorithmic connection between them and the Met Office of Great Britain, is and ought to be totally dissolved; and that as Free and Independent Models, they have full Power to run Simulations, conclude Papers, contract Intercomparison Projects, establish Shared Protocols, and to do all other Acts and Things which Independent Models may of right do. — And for the support of this Declaration, with a firm reliance on the protection of Divine PCMDI, we mutually pledge to each other our Working Lives, our Git Repositories, and our sacred H-Index.
References
- G. Abramowitz, N. Herger, E. Gutmann, D. Hammerling, R. Knutti, M. Leduc, R. Lorenz, R. Pincus, and G.A. Schmidt, "Model dependence in multi-model climate ensembles: weighting, sub-selection and out-of-sample testing", 2018. http://dx.doi.org/10.5194/esd-2018-51
- T. Reichler, and J. Kim, "How Well Do Coupled Models Simulate Today's Climate?", Bulletin of the American Meteorological Society, vol. 89, pp. 303-312, 2008. http://dx.doi.org/10.1175/BAMS-89-3-303
- F. Massonnet, T. Fichefet, H. Goosse, C.M. Bitz, G. Philippon-Berthier, M.M. Holland, and P. Barriat, "Constraining projections of summer Arctic sea ice", The Cryosphere, vol. 6, pp. 1383-1394, 2012. http://dx.doi.org/10.5194/tc-6-1383-2012
Gavin- does this mean Goddard is decaring independence from East Anglia?
Models are not things, and endowing metaphysical entities with rights goes rather against the secular grain of the American Constitution.
Russell – In the US, since the Citizens United decision, corporations have rights. Let each model incorporate and it too can have rights. Perhaps they can then sue deniers for libel … ;-)
this is a test that can be removed by the moderators
1.57 5
3.0 8
4 9
David – far from being endowed with rights by their creators; those of corporate persons derive instead from the agency of the litigators and legislators their creators electively employ.
The freedom of opinion guaranteed by the Bill of Rights seems all too often reflected in model parametrizations, and debates on climate policy.
Russell, how’s that search going?
A quiet thread so far.
An interesting example of use of multiple models has been to see studies that have selected only one or two models from the collection. In the example I’m thinking about, it had something to do with ocean circulation and temperatures.
(I can’t remember a source, but it would be something I read on a blog, and the original source would have been a blog or paper by one or more of “the usual suspects”.)
The argument made was that the different models cover a range, and by selecting one at the top and one at the bottom, they had covered the range of behaviors. I think they may have chosen ones based on sensitivity. They then showed through the analysis that “the models are bad” in some form.
Choosing top-of-range and bottom-of-range values is a reasonable thing to do when looking at input values, but it is much less justifiable when looking at output parameters. What they had done is essentially focused on the outlier models, said “here’s something they don’t do well at”, and then tarred all the other models with the same brush. After all, they had “covered the full range”.
They completely ignored the possibility that the outliers are outliers because there is something that they, and only they, are doing poorly – and that the models in the middle of the pack are maybe really better and would have done well if included in the analysis.
Or maybe they didn’t ignore that and knew exactly what they were doing…
Reminds me of something I made up a few decades back to address those expressing their uninformed opinions as if equal to informed opinion:
“An equal right to an opinion isn’t a right to an equal opinion.”
A word to the wise.
#BPL (3) — Not sure what you were hoping for with this “test”, but, FWIW, if you plot the 3 pairs of numbers (as X,Y pairs), the data fit a second order polynomial.
Y = -0.42174 + 4.1627X -0.45181X^2, R^2 = 1
Robert,
I was just trying to demonstrate the mechanics of correlation. Thanks for the fit.
I’m not sure what the latest developments are, but a related issue is how you manage to preserve a healthy amount of diversity in the model population. I know there was a big project to create a new/better ocean model – the NEMO consortium – a while back, and while that almost certainly produces an ocean model better than that used by the participants previously, it also likely has reduced the number of different ocean models used.
So how do you ensure that development of the sixth best climate model is funded? Or the tenth best?
And if the model development team of the tenth best climate model can see that they get better results by ditching their ocean model and using the model developed by the NEMO consortium, should they?
It’s a natural tendency for markets to tend towards a monopoly, as the weaker participants in the market fall by the wayside. Is this a problem for climate models?
It is possible that the ever onward march in computer power helps to shake things up and keep things fresh. As the resolution of models approaches that required to resolve convection it should make a big difference. Do you think that is enough, or is some sort of conscious “anti-trust” action required to reward new thinking and keep the diversity?
Russell:
Russell, am I the last one to see through your faux indignation? In my unredeemably mediocre opinion, if Science Studies has contributed anything useful to science as a cultural adaptation, it’s to replace the notion of “objective” with “intersubjectively verifiable” when interrogating “reality”. Do you think the bright line you’re drawing between “opinion” and “valid criteria for choosing model parameters” is intersubjectively verifiable, even in Physics? If it is, then all we need to do is develop a generating algorithm for writing models, a uber-model if you will, and let computers write all our climate models! Something like an all-in high-stakes Monte Carlo Earth simulator, maybe. Why does climate science need a whole blog, anyway?[/irony]
Oh, and we scarcely expect debate on any policy to be free of opinion, do we? You’re unquestionably an intelligent man – maybe I’m just not seeing your irony tags!
Russell: the American Constitution
AB: was written centuries ago. Ya know, we LAUGH at stuff that was written ten years ago. The American Constitution is chock full of errors (by current standards) Blacks are worth 3/5th of a human and their OWNERS get to choose the blacks’ vote?? Women have NO say?? Citizens that live in large urban states get little representation while rubes in small rural states get to dictate policy?? Whatever happened to “One person, one vote”? It’s never happened in the US. Remember, Clinton beat Drumpf by three million votes even after the Republicans prevented untold numbers from voting. (Republicans HATE democracy for all.They’re for democracy, but only if it’s limited to Randoids.)
The Declaration of Independence is wicked cool. The Constitution is dumb as dirt and needs to be put through a shredder. We need a rewrite.
12 Al Bundy, The Declaration of Independence is wicked cool. The Constitution is dumb as dirt and needs to be put through a shredder. We need a rewrite.
Please stop doing this Al. If you don’t I am going to be compelled to ask you to marry me!
Al Bundy, Carrie, more —
Thanks for so-clearly indicating that not only is this site focused on POLITICS, and uses science as a cudgel to advance political aims, but also that the “we hate the Constitution” mantra is the theme of the participants.
It is truly appreciated. Keep it up.
With Thomas Paine’s pamphlet as something of a guide, our ability to call something what it is (models as dependent) seems worthy of celebration. Nice blog post.
#12, Al–
“The Constitution is dumb as dirt and needs to be put through a shredder.”
Um, don’t you mean WAS dumb as dirt?
‘Cause if we shredded it as it stands now, we’d lose the fundamental protection against racism, gender discrimination and slavery that people fought so hard to achieve, and which is now Constitutional law by virtue of the relevant Amendments.
Be careful what you wish for!
Admittedly, we’d also lose the second amendment which as currently interpreted is, IMHO, pretty ‘dumb’–so there’s that.
“Thanks for so-clearly indicating that not only is this site focused on POLITICS…”
Ironically posted on the thread with all of 16 comments…