We’ve been a little preoccupied recently, but there are some recent developments in the field of do-it-yourself climate science that are worth noting.
 First off, the NOAA/BAMS “State of the Climate 2009” report arrived in mailboxes this week (it has been available online since July though). Each year this gets better and more useful for people tracking what is going on. And this year they have created a data portal for all the data appearing in the graphs, including a lot of data previously unavailable online. Well worth a visit.
First off, the NOAA/BAMS “State of the Climate 2009” report arrived in mailboxes this week (it has been available online since July though). Each year this gets better and more useful for people tracking what is going on. And this year they have created a data portal for all the data appearing in the graphs, including a lot of data previously unavailable online. Well worth a visit.
Second, many of you will be aware that the UK Met Office is embarking on a bottom-up renovation of the surface temperature data sets including daily data and more extensive sources than have previously been available. Their website is surfacetemperatures.org, and they are canvassing input from the public until Sept 1 on their brand new blog. In related news, Ron Broberg has made a great deal of progress on a project to use the much more extensive daily weather report data into a useful climate record. Something that the pros have been meaning to do for a while….
Third, we are a little late to the latest hockey stick party, but sometimes taking your time makes sense. Most of the reaction to the new McShane and Wyner paper so far has been more a demonstration of wishful thinking, rather than any careful examination of the paper or results (with some notable exceptions). Much of the technical discussion has not been very well informed for instance. However, the paper commendably comes with extensive supplementary info and code for all the figures and analysis (it’s not the final version though, so caveat lector). Most of it is in R which, while not the easiest to read language ever devised by mankind, is quite easy to run and mess around with (download it here).
The M&W paper introduces a number of new methods to do reconstructions and assess uncertainties, that haven’t previously been used in the climate literature. That’s not a bad thing of course, but it remains to be seen whether they are an improvement – and those tests have yet to be done. One set of their reconstructions uses the ‘Lasso’ algorithm, while the other reconstruction methods use variations on a principal component (PC) decomposition and simple ordinary least squares (OLS) regressions among the PCs (varying the number of PCs retained in the proxies or the target temperatures). The Lasso method is used a lot in the first part of the paper, but their fig. 14 doesn’t show clearly the actual Lasso reconstructions (though they are included in the background grey lines). So, as an example of the easy things one can look at, here is what the Lasso reconstructions actually gave:

‘Lasso’ methods in red and green over the same grey line background (using the 1000 AD network).
{kind=link}
It’s also easy to test a few sensitivities. People seem inordinately fond of obsessing over the Tiljander proxies (a set of four lake sediment records from Finland that have indications of non-climatic disturbances in recent centuries – two of which are used in M&W). So what happens if you leave them out?
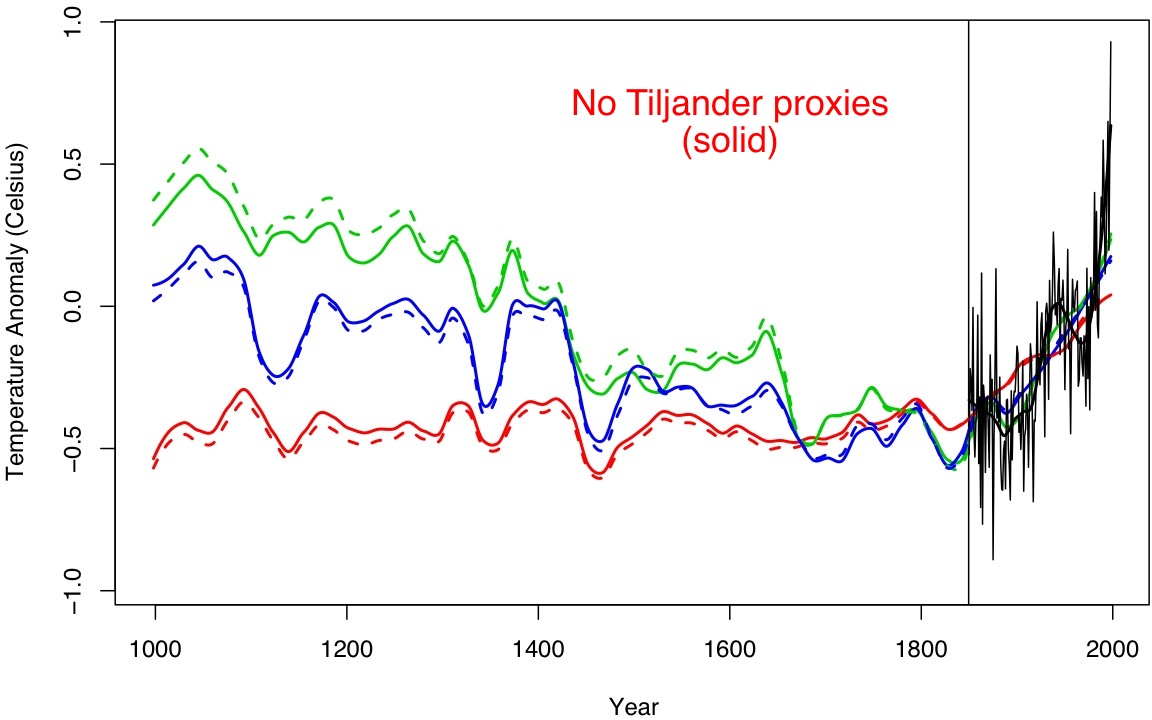
No Tiljander (solid), original (dashed), loess smooth for clarity, for the three highlighted ‘OLS’ curves in the original figure).
… not much, but it’s curious that for the green curves (which show the OLS 10PC method used later in the Bayesian analysis) the reconstructed medieval period gets colder!
There’s lots more that can be done here (and almost certainly will be) though it will take a little time. In the meantime, consider the irony of the critics embracing a paper that contains the line “our model gives a 80% chance that [the last decade] was the warmest in the past thousand years”….
Also the irony of a reconstruction with the straightest shaft since the original “hockey stick”. More slope, but still, pretty darn straight compared to the other reconstructions (as summarized in the NRC 2006 report) which showed a lot more interdecadal variability… makes the 20th century really stand out as a change in the long term system behavior…
“our model gives a 80% chance that [the last decade] was the warmest in the past thousand years”
I would be interested in knowing the next highest posterior probability for the warmest decade. Looking at “rolling decades” (as M&W do) yields a lot of 10-year periods (just shy of 1000, really). I would think that if a single 10-year period has an 80% chance at being the warmest, then that doesn’t leave much room for other 10-year periods to also have high probabilities. (although I may not have my Bayesian interpretation straight here…)
Thanks for the link to R. Here’s hoping I can figure out how to use it.
[Response: Unless you’re an experienced programmer or a polymath or genius with access to some good R books, don’t be in a hurry.–Jim]
recaptcha what is a cuounkno?
[Response: It’s an R function :)]
There are many comment about the normalisation based on hemispheric average temperature. This would overweight the northern data point, which would also explain why the curve is almost a carbon copy of the one of Kaufman.
I think there is a lot of misunderstanding of the 80% quote from McShane & Wyner. They started off the paper by supposedly showing that the proxy data is worthless, worse than random garbage, and then proceeded to go ahead anyway and calculate past temperatures based on that worse than random data. So I don’t think that they’re saying that there is REALLY an 80% chance that 97-07 was the warmest decade, but rather, given their model and the [edit – watch the inflammatory rhetoric] data, that that is the result you get. To use that quote out of the context that explains that the quote is based on [edit] data is misleading because it makes it sound like the authors are agreeing that there really is an 80% chance that 97-07 was the warmest decade.
[Response: Needless to say (except it isn’t), they demonstrate nothing of the sort. They use a single method (lasso) with relatively short holdout periods and show that it can’t beat some noise models. How does that demonstrate that the underlying data is ‘worthless’? All sorts of reasons might explain this – lasso might not br very good, their noise models are mis-specified, the validation metric is flawed, the holdout period too short etc. Think about ways that you could use to test this and try to be a little more dispassionate in addressing these issues…. – gavin]
M&W’s conclusion that the proxy data is worse than random data at predicting temperatures is hard to believe. Even if you think there is very little relationship between the proxies and temperature, it seems like there ought to be SOME relationship. At least slightly better than random data. If I was going to test M&W’s evaluation of the proxy data, probably the first thing I would do is create simulated proxy data by adding various amounts of noise to the thermometer record and then compare the noisy thermometer record to random data using M&W’s method. I suspect it may turn out that less noisy random data scores better than slightly noisier data that really does correlate somewhat well to the actual thermometer temperatures. The other thing that might truly be throwing off the correlation with proxy data is any residual contamination of UHI or other errors in the thermometer record that would not be present in the proxies.
When I referred to the data as worse than random garbage in my above comment, I was just trying to make clear what I thought M&W’s position on it was. I wasn’t necessarily agreeing with it. Hence the word “supposed”. I think you should make my comment whole, though it would perhaps be acceptable and less inflamatory to leave out just the word garbage.
Gavin:
In fact, one might wonder if they didn’t search for a method that wouldn’t beat some noise models (i.e. lasso) for the data at hand …
Oh, regarding tree rings, at least, you’d imagine they’d just proven that Liebig’s law of the minimum doesn’t really work, therefore a bunch of increases in ag production efficiency is no better than that which would’ve occurred randomly, and probably a bunch of other similar things.
The underlying problem, IMO, is that proxies are chosen for real, physical, reasons, and to say that some b-school profs have proven they don’t reflect a particular environmental signal runs right up against practical and successful applications in today’s real world.
[Response: Thank you. The beginning of their abstract’s second sentence reads: “The relationship between proxies and temperature is weak…” Well there’s an interesting finding, but damned if they didn’t hide it in a paper in a statistics journal!! I’m looking forward to the explanation of why temperate and boreal trees’ primary and secondary meristems go dormant during the cold season (= no growth) but those of tropical trees, which have no such season, do not, and why ITRDB tree ring data at temperature limited sites show such suspiciously high correlations between the growth rates of the different trees in a stand. The foresters and arboriculturists are going to be really upset at this news–they are under the impression that tree growth somehow or other responds to temperature. Ain’t that nuts?–Jim]
Mindbuilder:
You say that adding noise to the temperature record would be a good way to evaluate, but doesn’t that build in a bias in a way? If the noise is ‘noisy enough’ you’ll get the same data you had to start with (generally) when you average.
What bothers me the most is that the curve represents two data sets, proxies and thermometers. It is the thermometer records that make it look alarming.
[Response: Yes, that’s because they ARE alarming, at least to those who know the physical and biological ramifications of rapidly raising the planet’s temperature almost a degree C, and at a rapidly increasing rate at that.–Jim]
What basis is there for the assumption that two data series can be reasonably displayed on the same chart.
[Response: Correlation over their common interval.–Jim]
Also, Is there no proxy data for the past 150 years? If not, why don’t we go find some? If yes, can deploy the curve without the temp data so we can see what it looks like?
[Response: Yes, lots of it. That’s what the correlations with the instrumental are based on. And (2) yes, it’s been done in a number of papers, especially those exploring the tree ring vs T divergence phenomenon–Jim]
Some quick metacomments. (I have been too lazy to read the paper and the critiques, may do that later.)
R is currently a de facto standard in statistical programming, and well worth learning because of its popularity. R is not perfect, for example it is quite slow and has confusing scalar-vector semantics, and awkward N-D arrays compared to, e.g., Python’s numpy. But as a programming language, it is relatively modern.
Lasso etc.: Lasso or L1 regularization has been popular on predictive models because it gives sparse solutions – only part of the variables tend to contribute strongly. This comes directly from its interpretation as a prior with a strong peak at zero. In the predictive sense, Lasso may work a bit better than L2 (gaussian prior) with a huge number of variables, but it is not favored for inference, that is, where the coefficients of the model are interpreted, because as a prior it is unnatural. New evidence indicates that a Cauchy prior is a good compromise (Gelman et al.), but it may be numerically difficult in large problems (leading to non-convex optimization).
Without commenting the models of the M&W paper, going bayesian is in general good. Bayesian models make assumptions explicit, handling of missing data more principled, and allow hierarchical assumptions about the error structure. For example, different kinds of proxies may be tied together with common priors. But the wild range of possibilities may also be a downside in a politically charged issue like this.
BTW, “80% change of X given the model” means just what it says. If the model is bad, the result is meaningless. Just remember that you cannot really talk of probabilities without conditioning them on some model, implicit or explicit.
“our model gives a 80% chance that [the last decade] was the warmest in the past thousand years”….
Yeh, except, the paper was about the lack of reliability of proxies. They pretty much state they aren’t reliable. So, the statement above is referring only to the outcome of the model, not some view of reality of the authors. The model gave them that answer, only they don’t believe the model to be accurate.
Hope that helps.
[Response: What would help more is if you actually thought about it a little. How do they address reliability? They take a new method (‘lasso’) that is untried and untested in this context and compare it to noise models on holdout periods that are shorter than have been used before, using a metric that hasn’t been used before. If they don’t believe that their method is any good, then none of the conclusions hold about anything. I therefore doubt that it is actually what they think. – gavin]
I’m not remotely qualified to remark on the nitty-gritty statistical treatments in this M&W paper but what I found remarkably conspicuous was the cumbersome load of political content and what appears to be framing it carried. By the time I’d waded through the extended and arguably refracted history of the world of hockey stick enthusiasts I was left wondering not only whether I was reading Senate testimony as opposed to a scientific research article but also whether I should bother using any of my (tiny) precious mind reading the scientific appendix attached to the popular media piece comprising the first section.
Martin Vermeer mentioned another possible problem which I’ve found interesting.
http://scienceblogs.com/deltoid/2010/08/a_new_hockey_stick_mcshane_and.php#comment-2729979
What do you think?
In order to validate their methods, they use an interpolation task rather than an extrapolation task. That is, they fit the model on the temp. record, minus a middle chunk, and test how well their model can infer the missing middle part.
This has raised eyebrows. Clearly providing both endpoints makes it much easier to estimate the middle part. The fact that random-based model can “beat” proxy-based models at this task may be an artifact of the error function (RMSE on the unsmoothed outputs, IIUC – which I probably didn’t).
At any rate, the interpretation that “proxies can’t predict temperatures better than random processes” is itself a serious extrapolation!
I wonder if the RC gurus have an opinion on this particular point.
I’m in the process of writing my own advanced statistical software in VB2008 because I’m having so much trouble dealing with R. I don’t know if R even does things like unit root tests and cointegration regressions.
Jim: Thanks for the advice on R. I took the Algol 20 course in 1964
and did some self-study on LISP and a bunch of other languages between
then and now, but I much prefer hardware engineering over software.
I learned statistics as a physics undergrad and at the Army’s school
for quality control. I will hold off on installing R unless you can
point me to a free online course in it.
Climate confuser Bjorn Lomborg makes up a new story, copied by ‘news’papers around the world: A 7-metre sea level rise is no big deal, and costs only 600 billion per year to cope with: http://bit.ly/Nonsens
“Tokyo coped with 5 metre subsidence since the 1930s, so we can cope with sea level rise as well”. Forgets to mention that subsidence was stopped in 1975 (http://bit.ly/Toksub), and that Tokyo is still 6+ metres above sea level!
M&W shorter: `The data don´t work and are worse than random noise, but damned if they don´t reproduce a hockeystick. Gee, who ya gonna believe, me or your lyin´eyes.´
BPL [off-topic], try the tseries or urca packages.
Why does this site delete opposing comments so much? I don’t see such antics at sites such as wattsupwiththat or climateaudit? Are you guys agenda driven and trying to hide something? Inquiring minds want to know.
[Response: Case in point. Do you think your comment adds anything to the discussion on this topic? – gavin]
#18–Not to mention that Tokyo’s seafront is a little smaller than the world’s total built-up seafront–and far richer than the mean, to boot.
Well, the blog’s been a tad slow of late, but out in the real world I’ve enjoyed reading my local-language paper, with comments on recent extreme events by Gavin (in NYT) and particularly Stefan. If this is you being “preoccupied”, carry on!
But I know of and have submitted posts of substance in the past, yet you delete. [insults removed]
[Response: If you think that having a discussion about science revolves around insulting our integrity, you are very confused. I have absolutely no interest in playing games with you – either make substantive points, or don’t bother. Your call. – gavin]
I would like to see further discussion of the interpolation vs extrapolation debate as it relates to proxy calibration. The authors discuss this point in some detail and feel that the proxies should outperform noise in both cases. Also, empirical AR and brownian noise outperform the proxies in almost all blocks including the beginning and end which are more extrapolation based. Can you clarify?
[Response: Interpolation in a system with low frequency variability is always going to be easier than extrapolation. For instance, in a simple example take a situation that is flat, then a trend, then flat. If you take out a chunk in the middle, and fit red noise to the two ends, you have a lot of information about what happened in the middle. For extrapolation, all noise models will eventually revert to the mean of the calibration method, and so if that wasn’t actually the case, the proxies should outperform the noise. And of course the shorter the period you take out, the harder it is for proxies to outperform. There isn’t much difference between Brownian motion and AR(1) on these short time periods though. This is amenable to testing with the code provided (R_fig9[abc] for instance, but it takes some time to run). – gavin]
Gee, confirmation bias, much? You don’t think that wattupwiththat or climateaduit delete comments? The mind boggles.
[Response: Discussion of blogs comment policies on threads that are actually related to substantive issues, just leads to distraction. Let’s try to stay on topic please. – gavin]
One more question; in your GISS-USA-temp-anom-adjusted-for-UHI data set, why do you adjust the early part of the century down and the latter portion up? If you are correcting for UHI shouldn’t it be the other way around? Why cool the 1930s when cities were smaller, wouldn’t it have been even warmer if the cities were larger yet you adjust down? Makes no sense.
[Response: These are anomalies. It makes no difference whatsoever. Please at least try and address issues in the post. – gavin]
David Jones and I, of the Clear Climate Code project, will be taking part in the surface temperatures workshop at the Met Office, and I hope we may be able to contribute to the ongoing project. Steve Easterbrook should also be there, at my suggestion.
I always read, and try to check the comments, especially all those wonderful links, but rarely post as I lack the level of science training necessary to contribute. However, I do know English and logic, and am good at spotting fluffing and fudging, such as that in the recent Curry-Schmidt hot air balloon. And on that subject, Dr. Schmidt’s description of Dr. Curry’s qualifications and concerns garnered more respect from me than anything she said, which speaks reams to those attacking the former and this site for a lack of courtesy.
The idea that someone WUWT and CA are pure as the driven snow about comment moderation and RC is off the charts for prejudice would be laughable if it didn’t create an appearance that does not resemble reality.
One of the reasons I come here is to continue to educate myself, and I find that moderation is exactly as stated – gentle, patient, and sticking to science until the commenter begins to be more obvious, if less genuine, in spouting the party line in the fake skeptic movement.
The moving goalposts in the misinformation movement have recently trumpeted “unfair” moderation and lack of courtesy as more important than reality and facts.
This is wrong, and approaches evil, affecting as it does our future on the planet. Even without the convincing developments of the last 40 years of climate science and its expansion to cover a wide variety of evidence and disciplines, it should be obvious to the simpleminded that our planet is finite, our consumption increasing, imitators from the world previously unable to use so much are on the increase, and resources are being used up. Ever increasing difficulty in maintaining a supply of polluting fuels of convenience is continuing to make decades of government subsidies of fossil fuels instead of alternatives a more obvious scandal of pollution and waste. Does anyone even count the loss of those polluting substances, in addition to their obvious poisoning of our world?
So again, this is wrong, approaching evil.
[Response: What would help more is if you actually thought about it a little. How do they address reliability? They take a new method (‘lasso’) that is untried and untested in this context and compare it to noise models on holdout periods that are shorter than have been used before, using a metric that hasn’t been used before. If they don’t believe that their method is any good, then none of the conclusions hold about anything. I therefore doubt that it is actually what they think. – gavin]
Gavin, it is possible I’m reading it wrong, but the way I read the paper, is I first read the title to see what the authors were trying to determine. They didn’t state they were trying to ascertain if the last decade was the warmest or not. They wanted to see if proxies were reliable enough to make such statements with any degree of certainty. They selected(right or wrong) the method they thought most appropriate. Their methods gave them the 80% result. They later, and emphatically, state the proxies aren’t reliable enough to make such statements. Note, in this post, I’m not making a judgment as to the validity of their conclusions, I’m stating the 80% ratio isn’t part of their conclusions.
suyts: if your argument is that their model is rubbish, I think you may find quite a few people who agree with you. But if that includes the authors, one wonders why they published at all…. unless it was to generate column inches.
But I don’t expect criticism of the paper to focus on the model. For all it’s flaws, it’s not particularly interesting. The errors are obvious. But their claims about “reliability” are way off, and I expect those to attract wide criticism.
To be blunt: if they can’t extract the signal from the noise, that is because they are Doing It Wrong.
And their complaints about failing to predict the present warming when the last 30 years are withheld: that’s just plain moronic. I can’t wait to see this paper comprehensively dissected.
Finally: their jabs at climate scientists are just rude. Who allows them to publish stuff like that? I hope the paper gets some heavy editing before it is published.
As if we didn’t have enough examples of what happens when statisticians wander outside their domain knowledge and don’t bother to collaborate already!
I would just like to give you guys some credit for not jumping to conclusions as some other sites seem to have done. Since the code is supplied, and since you folks here should be able to actually test their work, I look forward to what I hope will be an even handed review of the work once it is more thoroughly looked at. As I have told others, this will either bear the test of time, or it won’t. Though certainly there will be those who cling to it or dismiss it one way or the other.
But again, props for not flying off the proverbial handle. Already too much of that on both sides of the fence.
Ho-hum. Same stuff, different day.
The FUDsters resort repeatedly to two memes, hoping to deliver themselves from the unpleasant conclusions of science: 1) the temperature record is unreliable, and 2) climate scientists are corrupt. Now that climategate has sunk beneath the waves of reality, they turn again to hopes they can break the hockey stick. Alas for the current celebration at WUWT, it is proving as obdurate as ever.
But deniers are indefatigable. One has only to look to creationists for an example foretelling the future of climate science denial; this latest flop will not deter then from cobbling together new ways to confuse the public and waste the time of their betters. One waits with weary resignation for the next pothole they will dig in the path of science.
“I think there is a lot of misunderstanding of the 80% quote from McShane & Wyner. They started off the paper by supposedly showing that the proxy data is worthless, worse than random garbage…”
Well yes, there would seem to be misunderstanding right there, and possibly even misunderstanding on the part of the authors.
The fact that high frequency rich signals (random or otherwise) used as covariates to a noisy signal were preferred over possibly physically relevant proxies by shrinkage estimation of a high dimensional model is neither particularly surprising, nor does it say much about the relationship between the proxy signals and the noisy signal.
If I show you a satellite image of two ants on Mount Kilimanjaro, don’t be surprised if a shrinkage model for processing the image spends all it’s parameters on Kilimanjaro and none of them on the ants.
Why is climate change a signal like ants compared to noise like Kilimanjaro? Because climate change is slow compared to the time scale on which the proxies are measured, and the proxies have chaotic (i.g. broadband) higher frequency components (which from the climate change point of view are noise). Now plain old mean square error (MSE) is a broadband measure – (Plancherel’s theorem) which means that MSE regards equal amplitude features in proportion to their bandwidth. So the climate change signal is swimming uphill in the MSE criterion just because it’s narrowband, let alone that it’s amplitude is small compared to higher frequency components. Picking MSE without some sort of frequency compensation was telling the model estimation to try and model something other than climate change. OK, the authors didn’t think that through. I’m not sure why they didn’t, though.
But when you use a high bias estimator (anything that reduces the parameter count down by orders of magnitude, as was used in this paper) then you run the risk of the estimator annihilating anything small, and in the MSE way of measuring things, that means that any narrowband feature may be ignored.
So it’s not surprising that a high-bias estimator locks onto high frequency content. And it doesn’t say much about the things it didn’t lock onto, either.
Barton Paul Levenson: “I’m in the process of writing my own advanced statistical software in VB2008 because I’m having so much trouble dealing with R. I don’t know if R even does things like unit root tests and cointegration regressions.”
R is a language, the free software alternative S. Together, these are by far the languages preferred by many, many, academic statisticians. A very large number of modern statistical techniques make their first appearance in R.
Although I have exactly zero use for cointegration and unit root tests, (which might seem odd coming from a professor of quantitative finance), this is the sort of thing that one can be sure there R will have plenty of available choices, as Googling “cointegration R package” shows.
In my previous career as a portfolio manager, up until the turn of the millenium, I wrote entire real time high frequency trading systems in S-plus (which is essentially equivalent to R). (Full disclosure disclaimer: in exchange for an S-plus product endorsement I got some extra support regarding source code they didn’t usually provide). So you can do quite a bit with R.
Anywhere there is a statistics department, there will be some people who are fluent in S and R, so maybe if you check with the local statisticians.
Note that currently, I use numerical Python (aka numpy) because of the seamless inclusion of the multithreaded linear algebra and support for memory mapped files (our data sets are on the orders of Terabytes). I would like to suggest you skip right to numerical Python, but it has a noticeably bigger learning curve than R.
‘The fire down below’: @Revkin interviews scientist Guillermo Rein (University of Edinburgh) on the environmental significance of underground peat fires: http://nyti.ms/RevPeat
My stats abilities may not qualify me to comment on the number-crunching part of this M&W paper, but putting that aside, firstly, something that struck me was the rather overtly political commentary that went on in places, especially in some of the introductory section – a lot of which seems to have been sourced via areas of media or politics. That raised a couple of eyebrows here.
Secondly, the viral way in which a pre-publication MS flew around the internet was, er, interesting. On WUWT I did comment along the lines that high-fives were being done in less time than it would normally take to read the abstract, although perhaps my language was a little less temperate than that. I guess it will be interesting to see how the final version compares with the pre-publication one…. of which several thousand copies are likely saved on various hard-drives…
Cheers – John
Help!
I need to simulate the SOI for another 100 years or so. I can’t relate the damn thing to anything, even by Fourier analysis (which I’m probably doing wrong). It just looks like a total random walk.
How can I simulate the distribution, given the mean, standard deviation, kurtosis, and skewness? Is there a mathematical technique for doing so? This is advanced stats, so anyone who can help… Au secours! Au secours! Sauvez moi!
Barton Paul Levenson @38 — Start by reading how to generate a sample from a Gaussian distribution.
hey BPL,
This might help (uses the probability integral transform).
#30 suyts:
But why then even bother to compute a worthless result?
Why am I reminded of “It isn’t happening, it’s not our fault, and anyway it will be good for us?”
A question, and two points of clarification.
First, thanks for the graphics that show various “Lasso” outputs with the Tiljander proxies omitted. This post’s “No Tiljander Proxies” figure with the six reconstructions (1000 AD – 2000 AD) is an extension of M&W10’s Figure 14. As such, it’s a little hard to interpret without reference to that legend.
According to Fig. 14:
* The dashed Green line is the M&W10 backcast for Northern Hemisphere land temperature that employs the first 10 principal components on a global basis.
* The dashed Blue line is the backcast for NH land temperature that employs the first 5 PCs (global), as well as the first 5 local (5×5 grid) PCs.
* The dashed Red line is the backcast for NH land temperatures that employs only the first PC (global).
All three dashed lines appear to be based on the use of the entire data set used in Mann et al, (PNAS, 2008)–both Tree-Ring proxies and Non-Dendro proxies.
This is an important consideration, as there seems to be general agreement that Mann08’s Dendro-Including reconstructions are not grossly affected by the exclusion of the Tiljander proxies. This point was made in Mann08’s Fig. S8a (all versions).
However, there has been much contention over the extent to which NH land reconstructions restricted to non-dendro proxies are affected by the inclusion or exclusion of the Tiljander varve data. See, for example, the 6/16/10 Collide-a-scape thread The Main Hindrance to Dialogue (and Detente).
Mann08 achieved prominence because of its novel findings: the claim of consistency among reconstructions based on Dendro proxies, and those based on Non-Dendro proxies. Mann08 also claimed that the use of Non-Dendro proxies in could extend validated reconstructions far back in time. This is stated in Mann08’s abstract (see also press release).
Thus, the matters of interest would be addressed if the dashed and solid traces in this post’s “No Tiljander Proxies” figure were based only on the relevant data set: the Non-Dendro proxies.
(The failure of Non-Dendro reconstructions to validate in early years in the absence of Tiljander was raised by Gavin in Comment #414 of “The Montford Delusion” thread (also see #s 483, 525, 529, and 531). While progress in that area would be welcome, it is probably difficult to accomplish with M&W10’s Lasso method.)
.
The first point of clarification is that the Tiljander proxies cannot be meaningfully calibrated to the instrumental temperature record, due to increasing influence of non-climate factors post-1720 (Discussion). This makes them unsuitable for use by the methods of Mann08 — and thus by the methods of M&W10 — which require the calibration of each proxy to the 1850-1995 temperature record.
.
The second point of clarification is concerns this phrasing in the post:
The “four lake sediment records” used in Mann08 are “Darksum,” “Lightsum,” “XRD,” and “Thickness.” The authors of Tiljander et al (Boreas, 2003) did not ascribe meaning to “Thickness,” because they derived “Darksum” by subtracting “Lightsum” from “Thickness.” Thus, “Thickness” contains no information that is not already included in “Lightsum” and “Darksum.”
In other words, there are effectively only three Tiljander proxies (Figure).
[Response: We aren’t going to go over your issues with Mann et al (2008) yet again – though it’s worth pointing out that validation for the no-dendro/no-Tilj is quite sensitive to the required significance, for EIV NH Land+Ocean it goes back to 1500 for 95%, but 1300 for 94% and 1100 AD for 90% (see here). But you missed the point of the post above entirely. The point is not that M&W have the best method and it’s sensitivities need to be examined, but rather that it is very easy to edit the code and do what ever you like to understand their results better i.e. “doing it yourself”. If you want a no-dendro/no-Tiljander reconstruction using their methodology, then go ahead and make it (it will take just a few minutes – I know, I timed it – but to help you along, you need to change the selection criteria in R_fig14 to be
sel <- (allproxy1209info[,"StartYear"] <= 1000) & (allproxy1209info[,2] != 7500) & (allproxy1209info[,2] != 9000)(no_dendro) and change the lineproxy <- proxy[,-c(87:88)]toproxy <- proxy[,-c(32:35)](no_tilj)). Note that R_fig14 does not give any info about validation, so you are on your own there. The bottom line is that it still doesn't make much difference (except the 1PC OLS case, which doesn't seem very sensible either in concept or results anyway). - gavin]BPL, I have a book call “El Nino: Storming Through History” which uses historical data going back several hundred years (can’t remember the author off hand), but you might be able to extract some info about the SOI from his data. It won’t be easy, but there is something so chew on in that book.
“The foresters and arboriculturists are going to be really upset at this news–they are under the impression that tree growth somehow or other responds to temperature. Ain’t that nuts?–Jim”
Wasn’t there a recent paper that showed crop yields went down with rising temperatures? Maybe precipitation is what has led us to the idea there is a correlation to temperature.
[Response: BIll there have been thousands of papers describing effects of T on plants over the years. The key point wrt tree rings is that sites are chosen to attempt to minimize the confounding of P with T, depending on which variable one is interested in (a lot of dendro sites focus on P don’t forget). If you went from 5 to 11 k ft in the Cascades for example, say Mt Jefferson , you could find many sites on steep, S-facing aspects that respond primarily to P. As you ascended to near treeline, and avoided such exposures, you would increasingly sample stands that are limited primarily by T. You could also find places where both could be limiting, which would require a more complex model to explain the variation.–Jim]
BPL : “I need to simulate the SOI for another 100 years or so. I can’t relate the damn thing to anything, even by Fourier analysis (which I’m probably doing wrong). It just looks like a total random walk.
How can I simulate the distribution, given the mean, standard deviation, kurtosis, and skewness? Is there a mathematical technique for doing so? This is advanced stats, so anyone who can help… Au secours! Au secours! Sauvez moi!”
There are lots of mathematical techniques for doing this; the obvious first cut would be to compute the distribution function of the maximum entropy distribution with the specified moments, which is from an exponential family, so if all you wanted was to sample from a distribution with specified first four moments, there you are. One could (and many do) argue from information theoretic considerations that the maximum entropy distribution would be the only distribution to have the given moments which did not contain additional “information”.
However I would think you want to sample from a space of realizations that are hard to distinguish from the actual ENSO process. In other words, you want to choose lengths of history which have the desired marginal information (the moments you mentioned) but which also have marginal distributions of time separated observations. In other words, if you knew that the ENSO was really an ARMA(2,3) process with some heavy tailed innovations, then you would want to use realizations of that process with innovations chosen from the appropriate distribution.
Now this is actually pretty hard to do if you cannot confidently write down the process which generated the ENSO data, which I suppose is the case. You don’t really know whether the process is this or that nonlinear differential equation, and you aren’t really sure what the distribution of forcing should be, etc. One assumes that you would like to believe things like inertial range turbulence (at least the 3-D stuff on small scales) tells you something about the things which will provide your innovations. However you’re not going to get a low dimensional process that way, and that is a bit of a problem.
What is pretty straightforward is to model the data with a high dimensional linear model (ARMA, but not in those coordinates) and then apply model reduction, Bayesian estimation, and shrinkage. Your model will usually have innovations closer to Gaussian than your original data, which takes the pressure off fancy modeling of the distribution of innovations.
You can also use this same machinery, but with the data transformed in various ways to include nonlinear aspects of the evolution. For example if instead of each observation x(t) being represented as that, you can represent each observation as a vector, say – v(t) = (x(t), x(t)^2, x(t)^3), and then a MIMO model for linear evolution of v(t) ends up capturing some nonlinear parts of the evolution. (You can check with a quadratic map y(t) = c y(t) (1 – y(t) to see how this can work). Now choosing such a nonlinear embedding is nontrivial, but there’s a lot of stuff lying around the machine learning yards of tricks for doing that – (look up Mercer’s theorem, the “kernel trick”, or, for the more mathematically adventurous,reproducing kernel Hilbert space methods in machine learning). And there are other approaches.
Strangely enough though, there are numerical models for the Southern Oscillation lying around that could save you the trouble of modeling it yourself. For example my thesis adviser actually did this back in 1991 (http://www.atmos.berkeley.edu/~jchiang/Class/Fall08/Geog249/Week13/gv91.pdf, also http://www.environnement.ens.fr/perso/claessen/ateliers/SSA/biblio/Vautard_Ghil_92.pdf). Using one of these would save you the trouble of cooking up your own.
On a vaguely related note (statistics journals: the last refuge?), McKitrick’s rejoinder to AR4 on surface temps was recently published in the new Statistics, Politics and Policy. Which aspires to publish articles “in which good statistical analysis informs matters of public policy and politics” – or was it the other way around? McK’s arguments were briefly discussed here a few months ago. Any prospect of getting a comment published? Or would that be too much flogging of a dead horse, already?
[Response: As I have stated before, these papers demonstrate only that if you are persistent enough you can get anything published – you just need to go further and further afield until you get reviewers who don’t know enough about the domain to realise what’s wrong. My enthusiasm for dealing with these issues is limited, but it is easy to see what is wrong with this latest variation. He has calculated the spatial pattern of the Arctic Oscillation, ENSO and PDO etc. and put in those patterns in with the multiple linear regression. The patterns come from a reanalysis, not the surface temperature dataset and so are mis-specified from the beginning (and he includes both the NAO and the AO which is redundant). But the main problem is that these patterns do not have an unknown random effect on temperature patterns! On the contrary, they are known very well, and the impact of each phenomena on the 1979-2002 trends in CRU can be calculated precisely. If you really wanted to correct his method, you would have calculated a new set of trends corrected for the indices and then done the regression. He did not, though it might be fun for someone else to.
However this is just a diversion, in his other ‘new’ paper with Nierenberg, he slides in a admission that, yes, indeed, there is spatial correlation of the residuals in the MM07 model (duh!), and since he knows that individual realisations of the GISS model come up with fits to the ‘socio-economic’ variables as good as he has calculated in the real world, the practical significance of these continued variations is zero. (Note that even though he has calculated the results using individual run, he has not reported them in his papers which only include the ensemble mean results and where he bizarrely claims they have the same spatial characteristics as individual runs – they do not). He is also still claiming that de Laat and Maurelis (2006) supports his results when they do not (recall they found a pattern in the satellite trends as well!). So, it is unclear what further repetition of these points will really serve since he clearly is not interested in getting it right. – gavin]
#41 Martin Vermeer
I imagine that they’d have to compute to get the results and then check the results. One can’t check results if you haven’t computed them yet. Don’t get me wrong, I’m not well versed in this kind of statistical analysis to say whether the methodologies were proper or not. I’ll wait for the publishing and read the back and forth before I’ll be able to make a determination. What I’m saying, is that to read some papers, one has to view statements contextually. As pointed out earlier, given the tone and tenor of the background and the conclusions, and given that the 80% comment is in the same paragraph that they state, “proxies cannot capture sharp run-ups….”, I would find it very odd that they are asserting the 80% probability. I’m not trying to rain on anyone’s parade, I’m just pointing out that there may be a different interpretation of that particular statement.
40 apeescape: Thanks for the interesting URL.
tom s — 21 August 2010 @ 10:27 AM
“…in [the] GISS-USA-temp-anom-adjusted-for-UHI data set, why [is] the early part of the century down and the latter portion up? [In] correcting for UHI shouldn’t it be the other way around?”
If the moderators will permit a partial repost of a comment I made in another thread – somewhat relevant to “Doing it yourselves” climatology –
Menne et al http://www1.ncdc.noaa.gov/pub/data/ushcn/v2/monthly/menne-etal2010.pdf, following the pioneering work done by Anthony Watts and his surfacestations.org volunteers, found “…no evidence that the CONUS average temperature trends are inflated due to poor station siting.” On the contrary, they found that the corrections made to the data resulted in “… bias in unadjusted maximum temperature data from poor exposure sites relative to good exposure sites is, on average, negative while the bias in minimum temperatures is positive (though smaller in magnitude than the negative bias in maximum temperatures).”
Because the basics of anthropogenic global warming are fairly straightforward – CO2 is a greenhouse gas, because of the lapse rate water vapor condenses or freezes out in the troposphere and acts mainly to amplify the effect of CO2, humans are burning a lot of fossil C and increasing the CO2 in the atmosphere, the surface of the earth is warming, the cryosphere is retreating, the climate that supports civilization is rapidly changing, and consequently we are facing an uncertain future – but the details are complex, it’s easy to “misunderestimate” the way climate works in detail.
For instance, the reradiation of IR from GHGs’ in the atmosphere back to the surface heats the surface; because of the density gradient in the atmosphere, and the lapse rate effect on water vapor, most of the action takes place near the surface, If the surface warms by 1 degree, then a constant adiabatic lapse rate would mean every altitude would warm by 1 degree. But a rising parcel of air doesn’t just cool by adiabatic expansion, but also by radiation, and more CO2 will increase the radiation, and increase the environmental lapse rate. But the radiative cooling is time dependent, and a steeper lapse rate will increase convection and decrease the time over which a rising parcel can radiate heat away,increasing the relative amount of adiabatic versus radiative cooling. Increased temperature will increase the absolute humidity according to the Clausius-Claperyon equation; a larger amount of water vapor will decrease the density of air, all else being equal, which will increase convection and the relative amount of adiabatic versus radiative cooling. But the additional water vapor will radiate heat away more quickly, having the opposite effect; however, when the temperature drops to where the water begins condensing, the latent heat released will decrease the lapse rate to the moist adiabatic lapse rate. Because of the different intramolecular forces between water molecules as vapor in air, water, and ice, the wavelengths of emission and absorption are shifted; some of the radiation from the water/ice droplets at the top of a cloud can escape to space because the atmosphere above it is transparent at its wavelengths, whereas the same radiation from droplets at the bottom of a cloud will be absorbed and re-emitted in random directions from the droplets above, including back down to the originating droplets.
Trying to figure out how all this “should” work in your head will make smoke come out your ears; one needs to read a lot of scientific literature, and do a lot of analysis assuming one has the knowledge. Most people don’t have the time or the math chops. Arguing “I think the climate scientists did it wrong” when one doesn’t know what the scientists did or how to do it is silly. Using different statistical methods and getting a different answer is hard, but usually the difference is a matter of accuracy, not basic principles – Idso shows a lower sensitivity, less temperature increase for a doubling of CO2, but still an increase. No statistical analysis of the proxy record will ever disprove any of the basics I stated above.
Figuring out which effects are dominant, and quantifying how large they are is important, but the current level of inaccuracy in our understanding of these processes is insufficient to invalidate the basics of AGW. Even prominent skeptics like Monckton, Lindzen, Spencer, Idso, McKitrick and Michaels accept the basics, and I suspect Watts, Goddard, and maybe even Morano do as well.
R is not that hard to learn. I use it exclusively nowadays. If you understand C programming then you should not find R too difficult. Hey, I learnt R without a C background. Barton, I think that you are really wasting your time developing your own statistical package when R will do it for you.