Last week there was an international media debate on climate data which appeared to be rather surreal to me. It was claimed that the global temperature data had so far shown a “hiatus” of global warming from 1998-2012, which was now suddenly gone after a data correction. So what happened?
One of the data centers that compile the data on global surface temperatures – NOAA – reported in the journal Science on an update of their data. Some artifacts due to changed measurement methods (especially for sea surface temperatures) were corrected and additional data of previously not included weather stations were added. All data centers are continually working to improve their database and they therefore occasionally present version updates of their global series (NASA data are currently at version 3, the British Hadley Centre data at version 4). There is nothing unusual about this, and the corrections are in the range of a few hundredths of a degree – see Figure 1. This really is just about fine details.
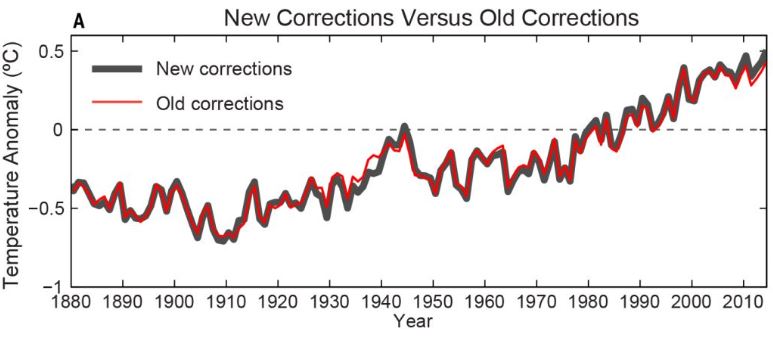
Fig. 1 The NOAA data of global mean temperature (annual values) in the old version (red) and the new version (black). From Karl et al., Science 2015
What got some people excited was the fact that the latest corrections more than doubled the trend over 1998-2012 in the NOAA data, which basically just illustrates that trends over such short periods are not particularly robust – we have often warned about this here. I was not surprised by this correction, given the NOAA data were known for showing the smallest warming trends recently of all the usual global temperature series. After the new update, the NOAA data are now in the middle of the other records (see Fig. 2). This does not change anything for any relevant finding of climate research.
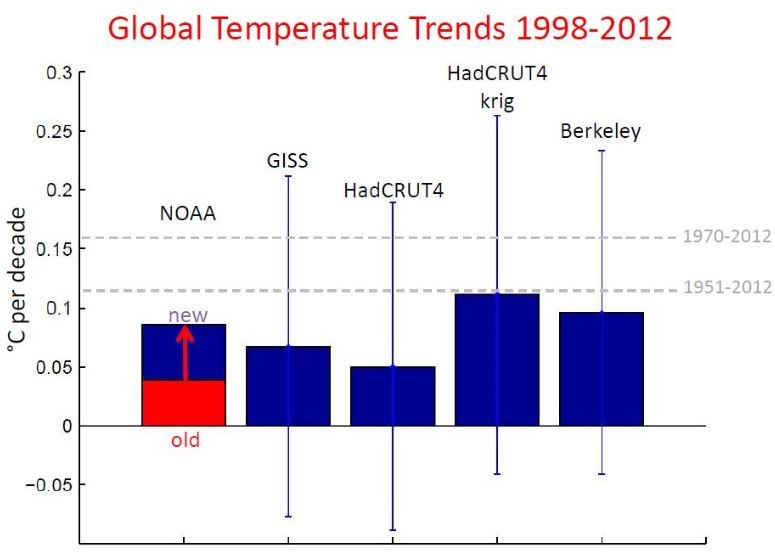
Fig. 2 Linear trends in global temperature over the period 1998 to 2012 in the records of various institutions. To calculate the values and uncertainties (±2 standard deviations) the interactive trend calculation tool of Kevin Cowtan (University of York) was used; follow this link for more info on the data sources. The red bar on the left shows the old NOAA value, the blue bar the new one.
In addition, the entire adjustment and the differences between the data sets are well within the uncertainty bars (also shown in Fig. 2). These uncertainties reflect the fluctuations from year to year, caused by weather and things like the El Niño phenomenon – these make the data “noisy”, so that a trend analysis over short time intervals is quite uncertain and significantly depends on the choice of the beginning and end years. The period 1998-2012 is a period with a particularly low trend, since it begins with the extremely warm year 1998, which was marked by the strongest El Niño since the beginning of the observations, and ends with a couple of relatively cool years.
Some media reports even gave the impression that the IPCC had confirmed a “hiatus” of global warming in its latest report of 2013, and that this conclusion was now overturned. Indeed the new paper by Karl et al. was framed around the period 1998-2012, because this period was specifically addressed in the IPCC report. However, the IPCC wrote the following (Summary for Policy Makers, p.5):
Due to natural variability, trends based on short records are very sensitive to the beginning and end dates and do not in general reflect long-term climate trends. As one example, the rate of warming over the past 15 years (1998 – 2012; 0.05 [-0.05 to 0.15] °C per decade), which begins with a strong El Niño, is smaller than the rate calculated since 1951 (1951- 2012; 0.12 [0.08 to 0.14] °C per decade).
The IPCC thus specifically pointed out that the lower warming trend from 1998-2012 is not an indication of a significant change in climatic warming trend, but rather an expression of short-term natural fluctuations. Note also the uncertainty margins indicated by the IPCC.
Imagine that in some field of research, there is some quantity for which there are five different measurements from different research teams, which show some spread but which agree within the stated uncertainty bounds. Now one team makes a small correction (small compared to this uncertainty), so that its new value no longer is the lowest of the five teams but is right in the middle. In what area of research is it conceivable that this is not just worth a footnote, but a Science paper and global media reports?
I have often pointed out that the whole discussion about the alleged “warming hiatus” is one about the “noise” and not a significant signal. It is entirely within the range of data uncertainty and short-term variability. It is true that the saying goes “one man’s noise is another man’s signal”, and to better understand this “noise” of natural variability is a worthwhile research topic. But somehow, looking at the media reports, I do not think that the general public understands that this is only about climatic “noise” and not about any trend change relevant for climate policy.
Technical Note: For calculation of trends (as far as they do not come from the paper by Karl et al.) I have used the online interactive trend calculation tool of Kevin Cowtan. In their paper Karl et al. provide (as the IPCC) 90% confidence intervals, while Cowtan gives the more common 2-sigma intervals (which for a normal distribution comprise 95% of the values, and thus are wider). In addition, Karl et al computed annual averages of the monthly data before further analysis, while Cowtan calculates trends and uncertainties straight from the monthly data (which I think is cleaner). To avoid showing inconsistent confidence intervals (and since the new data by Karl et al. are not yet available as a monthly data) I have not included intervals for the NOAA data in Fig. 2. In any case, the intervals are similar in size for all records if they are calculated consistently. The long-term trends shown in gray dashed lines hardly differ between the datasets and have very narrow confidence intervals (± 0.02 °C per decade for 1951 to 2014).
Links
RealClimate: NOAA temperature record updates and the ‘hiatus’
RealClimate: Recent global warming trends: significant or paused or what?
Why the fuss ?
Any way you graph it, the latest correction pales in comparison to the noise in the system
What I used to do in my class was show students a fabricated time series consisting of two components: random fluctuations about a mean of zero and a linear rising trend. The graph had many of the features of the actual graph of global temperature, including periods of rapid increase interspersed with “hiatuses” with smaller rates of warming, or even slight cooling. The main point was that it was impossible to get an accurate idea of the long-term behavior of the series by looking at short sections. My students were mostly non-science majors, but they seemed to get it — it really isn’t a particularly difficult concept!
Why did you not compare the Cowtan method on the RSS or UAH data series? One of these gives a slightly positive slope while the other yields a slightly negative one. While all five of the manually adjusted land (and sea) data sets yield positive slopes. Reason?
Leaving the data in monthly form seems to me to just add more “noise” rather than first calculating yearly averages.
[Response: Because this discussion is about surface temperatures, not those up in the troposphere. The satellite data actually require more adjustments than the surface measurements, there is a long history of those adjustments even to the extent of changing the sign of the overall trend. You can probably find quite a bit about this by searching our Realclimate archives. -stefan]
“The corrections were small in relation to the uncertainty”…
Is this statement true when it comes to the ARGO data? As I recall, +0.12C is not a “few hundredths of a degree”, nor is it small in relation to its previously ascertained instrument uncertainty. Do the ARGO people agree with you?
It seems like the whole ARGO project is a bust if all this money was spent on these measuring devices that can’t even improve upon an already known to be corrupted temperature measuring system. What all happens to all the conclusions about its perceived accuracy when it comes to depths of 2000m?
I noticed you didn’t include any satellite temperature data in your 1998-2012 (figure 2) graph of ‘the other records’.
If this is simply about such small adjustment numbers, then why not adjust the ship data to match the finer ARGO data instead? Or, conversely, why not just stick with the same temperature procedures and methods in use 70-80 years ago, and just adjust them to what we know them to really to be afterward? At least you’d have a more stable method of comparison. Are you to say that if we took the same measurements the same way as we did back in the 1930s, the temperatures WON’T show something 0.4°C hotter today? Are so many US state temperature heat records suspect because of this?
[Response: As Gavin showed in the previous post, the uncorrected raw data show more global warming. -stefan]
“Imagine that in some field of research, there is some quantity for which there are five different measurements from different research teams, which show some spread but which agree within the stated uncertainty bounds. Now one team makes a small correction (small compared to this uncertainty), so that its new value no longer is the lowest of the five teams but is right in the middle….”
Yes, climate science is clearly in better shape than some.
Consider The search for Newton’s g.
See another graph, i.e., this, rife with non-overlapping error bars.
I get upset when a journalist tries to put the word “believe” in my mouth. Here is how I answered one of them:
“Believe” is taboo
In science, we get more and more confident and eventually act like we believe something. When the odds are a billion to one in favor, that is almost equivalent to belief, but we never use the word “believe.” Believing is taboo. If you say you believe anything, you are labeled as not a scientist. Charlatans/preachers believe things. Scientists never believe anything.
So please never never never put the word “believe” in my mouth.
The real universe is based on probability and statistics. Certainty is wrong. Anybody who is absolutely certain is a liar. The Universe just doesn’t have certainty.
Probability and statistics is a laboratory course that changes you into a different person. Once you are changed, you can’t go back. You had best be a math or physics student before attempting to take it. It is the course that separates those who will be scientists from those who won’t.
Most physics majors change majors during their first Prob&Stat course. There is no royal road to mathematics, and Prob&Stat is probably the toughest undergrad course there is. As with all physics/math courses, it only gets harder in graduate school. There is definitely NOT any way to express it in English, plain or otherwise.
The Physics Prob&Stat course is transformative: It makes you into a different person. There is no going back. Absolute certainty exists only in the minds of people who do not understand.”
Stefan, you have just encountered the same problem. The people you want to explain it to will never understand you.
Interesting that people get excited, as though it is good news, on reports that the world’s temperature is increasing, and I quote from above: “What got some people excited was the fact that the latest corrections more than doubled the trend over 1998-2012”.
If the world’s temperature is increasing and you care about the world, then it is bad news, but on the other hand if you care more about winning the argument it is good news.
[Response: Maybe this is because I’m not a native speaker: I did not mean excited in the sense that they liked this correction, just in the sense that they thought this was a big deal. -stefan]
Thanks for the great post.
Pieter Steenekamp:
“What got some people excited was the fact that the latest corrections more than doubled the trend over 1998-2012″.
If the world’s temperature is increasing and you care about the world, then it is bad news, but on the other hand if you care more about winning the argument it is good news.
Excited does not necessarily mean pleased.
I wish it wasn’t big news – and I don’t think it changed a lot of minds one way or the other – but I do think your implied assumption is justified.
It’s “krige” … hence kriging (as opposed to “krigging”). Just because Kevin Cowtan gets it wrong in a couple of tables and a spreadsheet is no reason to perpetuate!
(I’m back under the rock now … sorry.)
> the latest corrections more than doubled the trend
No. They moved the fuzz at the edge of the gray area slightly on the charts. Nor do varying measurements of the force of gravity affect gravity. (John Mashey’s pointer above well worth following.)
What’s changing — slightly — is what we think we know.
It’s curious that the biggest correction on Figure 1 is actually between ~1933 and ~1942 ….
And nobody has commented on it, even members of the House of Lords.
Any explanations as to why this correction?
Thanks.
As a journalist, I certainly recall climate scientists pointing out the danger of cherry-picking a starting date for any so-called hiatus, and reported that to my readers. But I don’t recall anyone saying the “hiatus” could easily be an artifact of insufficient data. I do recall, and reported, scientists suggesting the hiatus, or slowdown, or whatever, might be due to an increase in the rate of heat storage in the ocean, or an increase of aerosols from Chinese coal plants or small volcanoes. I recall and reported the fact that no one ever predicted that warming should proceed upward in a smooth line–that periodic speedups and slowdowns were expected.
But nobody ever told me that the appearance of a slowdown in warming might easily go away with better data or better analysis. So the implication that the scientists knew this all along takes me by surprise. Or am I misinterpreting what you’re saying here? (That’s always a possibility, since I’m not a scientist myself).
As a European, I must remind that the global warming has been often illustrated here with the Hadcrut3 score, so it is very easy, on this side of the Atlantic, to understand why many questions came out, and why skepticism raised, and why proper scientists were embarassed to explain what was going on.
Hi,
I found this interesting quote from Svante Arrhenius. Make of it what you will.
” By the influence of the increasing percentage of carbonic acid in the atmosphere, we may hope to enjoy ages with more equable and better climates, especially as regards the colder regions of the earth, ages when the earth will bring forth much more abundant crops than at present, for the benefit of rapidly propagating mankind.”
He seemed to be in favour of global warming.
Hank: if measurements of g were treated like projections in climate science, some people would say that nothing that depends on gravity can be done until we know g *exactly*. :-)
Stefan, may I ask: What is the long term trend you have in mind? We see a striking rise in surface temps from 1910 to ca. 1940. But that looks a bit early to have been due to f.f. emissions. From 1940 through the late 1970’s we see, first, a distinct cooling trend, followed by a period with little or no trend. It’s only from ca. 1979-1998, only 20 years, that we see a strong upward trend apparently coordinated with an equally strong upward trend in CO2 emissions.
John Cook, in Skeptical Science, 2009, saw a similar problem over a somewhat shorter period:
“While CO2 is rising from 1940 to 1970, global temperatures show a cooling trend. This is a 30 year period, longer than can be explained by internal variability from ENSO [El Niño Southern Oscillation] and solar cycles. If CO2 causes warming, why isn’t global temperature rising over this period?” (http://www.skepticalscience.com/The-CO2-Temperature-correlation-over-the-20th-Century.html)
So if you don’t mind, I’d appreciate it if you could tell us precisely where your “long term trend” begins and ends. Thank you.
I got about 0.1 per decade simply using a Kalman smoother, graphed here: http://math.ucr.edu/home/baez/ecological/galkowski/SmoothingSplineToEstimatePointDerivatives.png, reported here: https://johncarlosbaez.wordpress.com/2014/06/05/warming-slowdown-part-2/
While it is true the ‘hiatus’ is less flat than originally thought, the trend 1999-2014 is lower than suggested by models. Indeed the trend, if pacific ocean cycles are taken into account would seem to show that the models are on average overestimating climate sensitivity and that rather than ECS being around 3°C, it is closer to 2.5°C or perhaps even lower. While this is small comfort as the resultant warming will be unacceptable, it does suggest that society has more time, perhaps a decade, to reduce Carbon emissions. This is good news.
In addition I am aware that modelers are looking hard at the climate sensitivities of their models and looking for reasons it may indeed be smaller than simulated. Can you comment?
The O’Floinn: Yes, Arrhenius thought global warming would be a good idea. He was writing in winter, in Sweden, in 1896. Also, he thought it would take 3,000 years to double carbon dioxide. He didn’t get the exponential-growth thing.
While the recent adjustments to the global temperature record are interesting, the observations 1999-2014 show less of a trend than previously determined. This is good news perhaps giving society more time to reduce carbon emissions. However, the resultant implication is that climate sensitivity is lower than predicted by computer models, down from around 3°C to 2.5° or even closer to 2°C.
Thus it would seem the models are missing something–aerosol or cloud forcing that would be essentially negative feedbacks. I am aware that modelers are hard at work looking for such mechanisms.
Can you comment?
V 17: The long-term trend is evident from, say, 1850 to 2014, where CO2 accounts for 80% of the variance of temperature anomalies. Plot the slope. Do a t-test of a regression of dT against time. Tell me what you find. Of if you don’t like HadCRT, do 1880-2014 and use NASA GISS or NOAA figures.
Victor,
If you continue to read the Skeptical Science post you linked the next two paragraphs read:
“The broader picture in this scenario is to recognise that CO2 is not the only factor that influences climate. There are a number of forcings which affect the net energy flux into our climate. Stratospheric aerosols (eg – from volcanic eruptions) reflect sunlight back into space, causing net cooling. When solar activity increases, the net energy flux increases. Figure 3 shows a composite of the various radiative forcings that affect climate.
When all the forcings are combined, the net forcing shows good correlation to global temperature. There is still internal variability superimposed on the temperature record due to short term cycles like ENSO. The main discrepancy is a decade centered around 1940. This is thought to be due to a warming bias introduced by US ships measuring engine intake temperature.”
It does not make you more convincing to post obviously misleading quotes.
Victor, think about particulate and sulphur aerosols from continuous and ever increasing burning of coal and oil in the complete absence of environmental controls in the post WW2 era and how that would affect incoming solar insolation. Bear in mind that CO2 from that same burning would also increase unabated during that same period.
Now think about the rapid introduction of effective legislation and regulations in Europe and North America to reduce those aerosol emissions and what the temperature trend would do soon after their introduction.
Now look at the temperature trend for the second half of the twentieth century. Really, it’s not that difficult.
Surely the quiet period was from about 2003-2013. 1998 was an outlier caused by a very strong ElNino. Temperatures didn’t approach it until several years later.
At 17 (Victor), I may be off-base, but didn’t they just cover this two posts ago?
https://www.realclimate.org/index.php/archives/2015/05/global-warming-and-unforced-variability-clarifications-on-recent-duke-study/
“We found that unforced variability is large enough so that it could have accounted for multidecadal changes in the rate-of-increase of global average surface temperature over the 20th century.”
If I read that right, it’s correct that ENSO can’t account for it. It’s likely attributable to AMO and other longer-period oscillations.
This does not necessarily explain the observed variation. I’ve seen other analyses point to e.g. hypothesized ill-quantified changes in aerosols and particulates. It just says that you don’t necessarily have to explain it, i.e., that not every multi-decade trend requires explanation via forcing. Such trends may (or may not) occur as a result of internal variability of the earth-atmosphere system.
Those results are new and so would not have been factored into the cited skeptical science analysis.
The article then goes on to nail the key issue, in that internal variability is not large enough to account for 20th century overall trend. So that gives the empirical answer. Somewhere between a few decades and a century is long enough.
Charles Keller wrote “the observations 1999-2014 show less of a trend than previously determined.”
Charles, what you are missing is that the observations for 1999-2014 don’t show the long term trend, period, because 15 years is simply too short a time span for the trend to be resolved from the “noise” of short term natural variability, which means it tells you nothing at all about climate sensitivity. What it does tell you is that over short time spans natural variability can overwhelm the underlying long term trend.
See
https://tamino.wordpress.com/2015/04/30/slowdown-skeptic
and
https://tamino.wordpress.com/2015/01/20/its-the-trend-stupid-3/
and
http://moregrumbinescience.blogspot.ca/2009/01/results-on-deciding-trends.html
CK 20,
15 years isn’t enough to tell a climate trend. You need at least 30.
http://bartonlevenson.com/30Years.html
http://bartonlevenson.com/NoWarming15Years.html
@Richard Hawes, from the previous post on this site, it seems that difference is due to “bucket” corrections. Someone more knowledgeable than I may be able to help you explain what that is, or perhaps the google will help. Cheers.
“There is some variation around the 1940s because of the ‘bucket’ corrections – See more at: https://www.realclimate.org/index.php/archives/2015/06/noaa-temperature-record-updates-and-the-hiatus/#sthash.hXtDpQck.dpuf“
#22 Michael, first of all I asked a question: when did the long term trend referenced by Stefan begin and when did it end? Still haven’t received a reply, but I can wait, no problem.
Secondly, regarding John Cook’s concern regarding the lack of trend over “a 30 year period,” I’m very aware of the hypothesis he offers by way of explanation. I analyze his explanation in my book. However: a hypothesis intended to provide reasons for the absence of an expected trend does not automatically produce the expected trend. A trend (or lack of trend) will remain, regardless of how reasonable the explanation might seem. And if his observation regarding the lack of warming trend over such a long period is accurate (and it certain seems consistent with the data), then it looks to me like there was, in fact, no long term trend after all. That doesn’t mean the lack of a trend can’t be accounted for by some hypothesis. But no hypothesis can produce a trend that never existed in the first place.
In other words. Regardless of what one might want to claim regarding what might have caused the trend to not appear in the data, the lack of trend remains in the data regardless, and the claim of a long term trend cannot, therefore, be maintained.
“I don’t recall anyone saying the “hiatus” could easily be an artifact of insufficient data.”
– See more at: https://www.realclimate.org/index.php/archives/2015/06/debate-in-the-noise/comment-page-1/#comment-632625
Mike, not sure how far back you want to go. But the clearest voice saying this has been statistician Tamino. For example, here is a piece describing a paper he co-wrote in 2011:
https://tamino.wordpress.com/2011/12/06/the-real-global-warming-signal/
There’s also the story about the discussion of ‘the pause’ in AR5; the comments of the government of Germany may be of some interest in this connection:
https://www.ipcc.ch/pdf/assessment-report/ar5/wg1/drafts/WGIAR5_FGD_FinalDraftSPMComments.pdf
> Victor … Still haven’t received a reply ….
The real scientists don’t appear on command to retype the frequently questioned answers — that’s why others have repeated the pointers to sources for you to read. Again, Statistics 101 is what you’re lacking here. It will change your view of the world if you pass the course. Or, since you claim to be an academic, talk to one of the reference librarians about how to ask better questions. You can do it.
Victor wrote on 17 Jun 2015 @ 9:22 PM,
“…the lack of trend remains in the data regardless, and the claim of a long term trend cannot, therefore, be maintained.”
There is no lack of an underlying, long term, ongoing and still positively accelerating global warming since the 1800s in the data. If you actually want to see this still positively accelerating global warming starting in the 1800s in the data in a very clear and simple graphical representation and if you accept the existence of up to 60 year oscillations such as the most general one, the NMO of Steinman, Mann, and Miller (2015) (which combined the AMO and the PMO [a term they used to denote the apparent up to 60 year oscillation in the PDO]), then a 60 year running mean (a 60 year moving average) shows this quite nicely, and here it is:
http://www.woodfortrees.org/plot/gistemp/mean:720
This graph gets rid of all these multidecadal oscillations of up to 60 years. It shows a graph of global warming since the 1800s that clearly seems to follow the path *not* of a straight line but of a *positively accelerating curve* that shows no sign of slowing down even as we speak. (By “positively accelerating curve” I mean the curve of a convex function, a function whose second derivative on the given interval is positive).
(Note: This graph of a 60 year running mean was given by commenter Olof twice at Open Mind, in the comment threads under the articles
https://tamino.wordpress.com/2015/04/30/slowdown-skeptic/
and
https://tamino.wordpress.com/2015/05/19/response/
in which articles and in comments under these articles Tamino showed via statistical analysis that the global warming underlying all this shorter and longer term variability is positively accelerating, consistent with what the 60 year running mean graph clearly shows in a glance.)
I note that this phenomenon of the positive acceleration seemingly showing no sign of slowing down in the 60 year running mean essentially includes all the years covered by the 30 year running mean seen at this article
http://www.skepticalscience.com/global_warming_still_happening.html
which includes all the *mere slowdown* since around 2000 and all the *actual downturn* 1940s to 1970s, and that this difference in *mere slowdown* and *actual downturn* is consistent with an upward increasing cycling curve suggested by the 30 year running mean oscillating around a still positively accelerating curve suggested by the 60 year running mean.
That is, when we compare the 30 and 60 year running means, we see the broad effect of the NMO appearing (becoming more apparent) and then disappearing to the point of seeing essentially nothing in the 60 year running mean but the raw, continuing positive acceleration of AGW. That is, this graphical information makes it very easy and clear to see that not only is it true that AGW attribution is clearer and predictions are more certain with the longer the run, but that the long term global warming underneath the NMO oscillation is not following the upward path of merely a straight line but as the 60 year running mean graph shows, it is following what seems to be the upward path of a positively accelerating curve that shows no sign of slowing down even as we speak.
(If these links don’t work, then try Google images, which shows these graphs when we enter “30 year running mean” and then when we enter “60 year running” with the parentheses.)
Final point, to anticipate an objection to a 60 year running mean: As Steinman, Mann, and Miller showed, the NMO with its up to 60 year oscillations exists, and so it’s about time to fully and appropriately recognize this fact and all its implications.
#22 Barton Paul Levenson: “The long-term trend is evident from, say, 1850 to 2014, where CO2 accounts for 80% of the variance of temperature anomalies.”
Well, here’s a graph covering that period (actually three): http://www.abc.net.au/news/2015-02-02/global-average-temperature-anomaly-281850-201429/6064298
I don’t see an upward trend until ca. 1910. Things are definitely warmer now than they were in 1850, I’ll grant you that. But a difference is not the same as a trend, no? Now from 1910 we see a rather steep upward trend culminating ca. 1940. I’m wondering how significant CO2 emissions could have been back then. Certainly negligible compared to emissions during the latter quarter of the 20 century. Yet the earlier trend appears just as steep as the later one (from 1979-1998).
Then, as Cook points out, we see a long period with little or no trend in either direction, followed by another steep upturn till roughly the turn of the century. Which, as far as the period beginning in 1850 is concerned, amounts to two uptrends of 30 years and 20 years respectively, interspersed with a no trend period of roughly 30 years, preceded by a no trend period of 60 years.
So I’ll repeat my question: where is the long term trend?
V 30: the lack of trend remains in the data regardless,
BPL: Do you understand what a “trend” is and how it’s measured? Do you know how to calculate a trend? Have you ever taken an introductory statistics course?
(#17, #30) Victor, not to answer for anyone else, but how about a long-term trend starting around the beginning of the 20th century continuing on to the current day? During some periods there may be short-term trends that are a little steeper or a little less steep, but that’s noise for you. Certainly, other factors overwhelmed the greenhouse signal from about 1940-1970 (as mentioned in the skepticalscience.com link you incompletely cited), but that’s the only period during which you can genuinely argue for anything like a hiatus (see https://tamino.wordpress.com/2015/04/28/graphs-by-the-dozen/). But even with that “hiatus,” the long term trend is significant in both the statistical and practical sense of the term.
You really need to get over your obsession with (totally unsurprising) blips in the trend. It’s most tiresome trolling on this blog.
Barton squarely hit the nail when he asked Victor if he understands what a “trend” is and how it’s measured.
“It’s most tiresome trolling on this blog.”
Come on people, that’s what Victor does. The only reason to respond to him is for the benefit of naive lurkers for whom he might strike a random chord. How many such innocents can there still be? And how often does he actually say anything remotely reasonable?
Before rising to his bait, please weigh the inevitable noise cost against any possible signal benefit.
#34–Victor said–almost asking a question–“I’m wondering how significant CO2 emissions could have been back then.”
I’m not sure what contemporary scholarship has to say about early 20th century emissions, but Guy Callendar considered the matter closely in his groundbreaking 1938 paper:
http://onlinelibrary.wiley.com/doi/10.1002/qj.49706427503/epdf
Here are a few points:
1–“By fuel combustion man has added about 150,000 million tons of carbon dioxide to the air during the past half century. The author estimates from the best available data that approximately three quarters of this has remained in the atmosphere. The radiation absorption coefficients of carbon dioxide and water vapour are used to show the effect of carbon dioxide on sky radiation. From this the increase in mean temperature, due to the artificial production of carbon dioxide, is estimated to be at the rate of o.oo3C. per year at the present time. The temperature observations at meteorological stations are used to show that world temperatures have actually increased at an average rate of o.oo5°C. per year during the past half century.”
2–“The artificial production at present is about 4,500 million tons per year.”
3-Callendar considered the actual increase in atmospheric CO2, and arrived at the conclusion that from 1900 to 1930, concentrations had risen from ~274 ppm to ~290 ppm, or about 6%. That’s fairly close to 0.5 ppm per year, or about a quarter of the rate we see today.
I’d characterize that as ‘small by modern standards, but far from inconsiderable.’
To be sure, as correct as Callendar was about many things, opinion today is that he did not detect an anthropogenic warming signal. After all, the only information anyone had on climate sensitivity was Arrhenius’s work in 1896, and no-one, including Arrhenius, would have claimed that that was more than a good first cut at the problem. So it wasn’t unreasonable to ask, as Callendar did, whether a 6% rise in CO2 might not have a measurable effect.
But there is a difference between the existence of a warming influence and the detection of same. Consider a quiet concert hall: there will be a ‘noise floor’ nevertheless: in fact there are standards for such things, with the most commonly specified being a noise curve referred to as “NC-15”.
Suppose you play noise approximating the spectrum of the NC-15 curve over loudspeakers, beginning inaudibly and slowly increasing the playback volume.*
At which point is the signal detected? And does that point also mark the point at which the signal becomes ‘real’–even though it is demonstrably being played prior to the point of detection?
*By the way, somewhat similar investigations have actually been made:
http://www.caa-aca.ca/conferences/isra2013/proceedings/Papers/P061.pdf
Uh, guys, Victor’s been round this several times already.
Asked and answered (or not answered) the same questions.
https://www.google.com/search?q=site%3Arealclimate.org+Victor+NEAR+“Statistics+101”
Mike Lemonick @ 13 — The World Meteorlogical Organization defines climate (temperature) as 30 or more years of measurements. Barton in
http://bartonlevenson.com/30Years.html
attempts to explain the statistical reason for this. Grant Foster, a professional consulting statistician, offers
https://tamino.wordpress.com/2015/04/30/slowdown-skeptic/
Also see comment #33 above.
Climatologists are supposed to know this. However, there are many subspecialities and not practitioners are sufficiently aware of the subtleties of the statistics. However, scientists like me how are amateurs of climatology by who have been around a long time were never fooled by a claim of “hiatus”.
I agree with Mal Adapted and Hank Roberts regarding Victor. He is not an honest broker of scientific information. Don’t bother.
Steve
#40. Yes, Hank, I’ve raised the “long term trend” question before. What’s new is my discovery of the observation by John Cook at Skeptical Science, who also noticed what looks like a discrepancy “from 1940 to 1970” (to me it looks more like 1940 to 1979, closer to 40 years). And yes, he presents an interesting hypothesis to account for it (based on research by Hansen et al., which for some reason he fails to cite). What interests me most, however, is his willingness to acknowledge the problem. (Whether he or Hansen actually made the “anomaly” go away is another issue.)
Let me suggest, for all those responding to Victor, looking back at my question to Tim Beatty #73 and his response at #79 on the previous thread.
That seems to me the proper way to deal with this, for Victor and others:
-What’s the difference? What exactly is the question you are trying to answer? What would it mean if there were a change in the slope of the best fit to the data?
Otherwise, you are falling into the trap of validating their claim that there is a “controversy”, as in “teach the controversy.” You are arguing about a minor variation and statistical definitions, but they are by implication arguing that the underlying principles are in doubt:
Either GHG physics is wrong, or the calculations of anomalous back-radiation are wrong, or there really is that magic undetected feedback/thermostat that all the evidence says is beyond improbable.
Hence my often impatient rants about this endless focus on GMST; this is their agenda, not yours.
In the end, further refining GMST doesn’t matter that much; bad effects are local, and we need to prioritize and better characterize those systems that directly hurt humans.
> Victor … what’s new is my discovery …
Correction: it’s news to you; it’s not a discovery. It’s old history.
https://tamino.files.wordpress.com/2010/08/emission.jpg?w=500&h=404
You’ve failed to read Spencer Weart’s history
(or fail to remember reading it).
You’ve learned nothing from Tamino’s clear, simple posts.
And you want attention.
About the cooling from 1940-1976 remember it was probably due to sulphate Aerosol emissions. somebody reviewed the data from the period and found there was a small warming trend at night, when screening sunlight didn’t reduce temperatures. So it must have been global dimming. Around 1970 with the introduction of clean air legislation in the industrial counties the cooling stopped.
Thanks dP — the warming trend at night was the key search phrase. Here’s a few sources on that:
https://www.google.com/search?q=cooling+1940s+sulfate+emission+day+night+temperature
A plot of NASA GISS global temperature (monthly) vs. Mauna Loa CO2 from 1959 (start of ML data) to the present reveals three distinct periods: 1) 1959 – late 1970s basically flat 2) late 1970 to late 1990s temperature increasing 3) late 1990s to present, little to no correlation between global temperature and CO2 – shotgun scattergram except flat, call it hiatus, call it what you like. In Phase 1 the period notably goes back to the mid 1940s as noted by several commenters. In Phase 3 the so called current hiatus or call it what you want… the X-Y cross plot reveals that all the variability in temperature is due to “not CO2.” Two alternative suggestions for this latest hiatus is the period of time is simply too short to draw conclusions from and will correct back to the trend line; while some might suggest that other factors are exactly canceling out the effect of CO2. Which is it? Answers that say “probably” this is happening … and “likely” that is happening … are just speculation. The facts will reveal themselves over the next ten years, so you just need to be patient. http://wattsupwiththat.com/2014/09/12/a-look-at-carbon-dioxide-vs-global-temperature/ and http://wattsupwiththat.com/2015/04/22/a-statistical-definition-of-the-hiatus-in-global-warming-using-nasa-giss-and-mlo-data/
DW 48,
Sample size matters. Try plotting all 150 years of data. Excerpting a small section that seems to prove what you want is called “cherry-picking,” short for “the fallacy of enumeration of favorable circumstances.”
> Danley Wolfe … “probably” … and “likely” … are just speculation.
Nope. Probability is what science offers.
Statistics 101 would change your view of the world.
Try it. It can’t hurt you to learn how to draw conclusions from data.
You’re promised certainty from religion, and you get proof from mathematics.